| SQL Workshop – Having Clause With NULLs |
| Written by Nikos Vaggalis | |||||||||||||||||||||
| Thursday, 05 November 2015 | |||||||||||||||||||||
|
SQL Workshop is where we confront real world scenarios that SQL devs face on a day to day basis, especially when having to maintain legacy systems. This one looks at the problem of handling partially delivered orders. For this example imagine that you are in charge of an order processing system for a large corperation Let’s begin with an Order with two items:
Each order item can be partially delivered, as shown by the difference between quantity_ordered and quantity_received. In this case, an order has been placed for 845.1 LT of Unleaded and so far 711.440 LT of it has been received. A second order has been placed for 257.8LT of Diesel and 99.380 LT of it has been received.
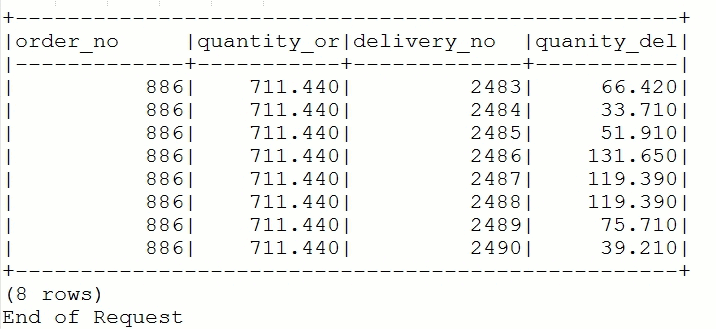
Also, each Item of each Order can be individually as well as partially delivered. In this case we’ve ordered two items but only item 98001005 has been delivered ,(98003002 has not yet been received at all) although partially, with Delivery numbers 2483 to 2490, with all of them summed up making up the 711.440 LT so far received:
Each delivery has a corresponding delivery confirmation:
Delivery 2483:
Delivery 2484:
Delivery 2485:
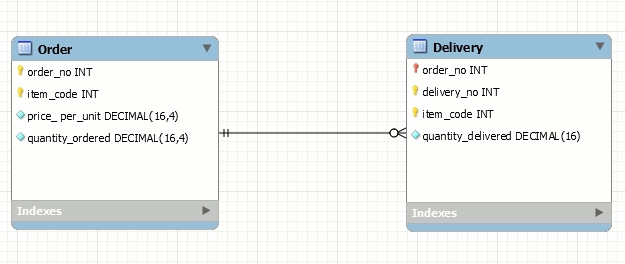
Here is the underlying data model which maps this relation:
Identifying relationship, 1:m, mandatory on Delivery’s end, optional on Order’s end
The equivalent result set would be: Query1
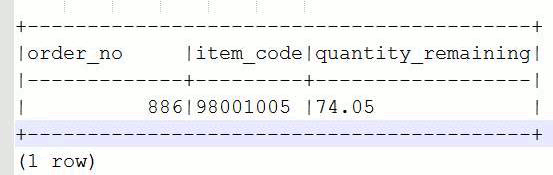
If we add all entries of quantity_delivered we get a sum of 637.390, therefore there is 711.440 - 637.390= 74.05 LT outstanding.
We need the user application to keep track of those sums and be aware of the outstanding quantities. Furthermore we want to present the supplier with the outstanding quantity so that he can either do a single Delivery covering the whole amount or do as many partial deliveries as required to equal that total
There are a few ways to go about it from within the user (UI) application:
We will of course go with the final option and formulate the following SQL:
select d.order_no, d.item_code, d.quantity_ordered - sum(y.quantity_received) as quantity_remaining from Order d inner join Delivery y on y.order_no = d.order_no and y.item_code = d.item_code group by d.order_no,d.item_code, d.quantity_ordered
Upon execution we are confronted with an error: E_US0B68 line 1, Illegal expression in the HAVING clause which means that we can only use aggregate functions inside the having clause, therefore d.quantity_ordered must be used as an argument of a function of that kind.
To find the source of the error means looking back to Query 1. We see that quantity_ordered is being repeated for each Delivery row, so doing a sum as: having (sum(d.quantity_ordered)> sum(y.quantity_received)) would erroneously produce : (711.440 x 8 > sum(y.quantity_ ordered))
What about max ? having (max(d.quantity_ ordered)> sum(y.quantity_received)) will always produce: having (711.440 > sum(y.quantity_ ordered)) or fully interpolated : having (711.440 > 637.390) which makes max the sole candidate.
Rewriting the SQL as:
select d.order_no, d.item_code, d.quantity_ordered - sum(y.quantity_received) as quantity_remaining from Order d inner join Delivery y on y.order_no = d.order_no and y.item_code = d.item_code group by d.order_no,d.item_code, d.quantity_ordered
results in:
There is one slight complication, however: The optionality in the data model allows for there to be an Order without any Delivery yet. This means there could be rows in the Order table for a given order without any related rows in the Delivery table, i.e. sum(y.quantity_received) is NULL. So to play along we must rewrite the query to use a left join and check for NULLS within the having clause:
select d.order_no, d.item_code, ifnull(d.quantity_ordered - sum(y.quantity_received),0) as quantity_remaining from Order d left join Delivery y on y.order_no = d.order_no and y.item_code = d.item_code group by d.order_no,d.item_code, d.quantity_ordered max(d.quantity_ordered)>sum(y.quantity_received) )
Astute readers will also have noticed another way in which the data model is problematic : quantity_ordered is repeated for every row of the Delivery table as demonstrated by Query1) something that could have been avoided if a better design was in place. Nevertheless, inherited cases like this that cannot be rewritten but only patched, offer an excellent testbed for sharpening your problem solving abilities and expanding your SQL skills.
Other SQL WorkshopsSQL Workshop - Removing Duplicate Rows SQL Workshop - Selecting columns without including a non-aggregate column in the group by clause SQL Workshop - Subselects And Join
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.
Comments
or email your comment to: comments@i-programmer.info |
|||||||||||||||||||||
| Last Updated ( Thursday, 05 November 2015 ) |