| Improve SQL performance – find your missing indexes |
| Written by Ian Stirk | ||||||||
| Monday, 17 October 2011 | ||||||||
|
Missing indexes are one reason why an SQL query takes longer (much longer) to complete. Here's how to find out about them and fix the problem.
In my previous article, Identifying your slowest SQL queries, I introduced the use of Dynamic Management Views (DMVs) to quickly and easily identify your slowest queries. I ended the article by saying that missing indexes can be a major reason why your queries might be running slowly. In this article I will look at identifying these missing indexes. Indexes are typically the primary means of improving SQL query performance. They allow you to retrieve the required data quickly. You can see the importance of an index clearly when you try to find something in a book; without an index it can be quite troublesome. As useful as an index is, the reverse illustrates how detrimental a missing index can be on SQL query performance. I’ve known cases where queries have taken more than 4 hours to run, and when missing indexes were added, these same queries completed in less than 5 minutes. There are many reasons why indexes may be absent. Perhaps the developers were inexperienced or unsure of how the underlying data was to be used. Perhaps the application that uses the data has changed and now needs to use other indexes. Perhaps it was thought (erroneously) that creating a foreign key relationship automatically creates an index on the same columns. Let’s see how we can quickly and easily identify these missing indexes using DMVs. Finding your missing indexesWhen you run a SQL query, SQL Server determines what indexes it would like to use, if these are not available, it makes a note of them. You can see details of these missing indexes by using DMVs. The following SQL will identify the top 20 most important missing indexes, ordered by impact (Total Cost) on your server: SET TRANSACTION ISOLATION LEVEL The script starts with the statement SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED. The purpose of this is to ensure the SQL that follows does not take out any locks and does not honour any locks, allowing it to run faster and without hindrance. The TOP 20 clause together with the ORDER BY clause, ensure we only report on the top 20 most important missing indexes. Details of the relevant DMVs in the query are given below:
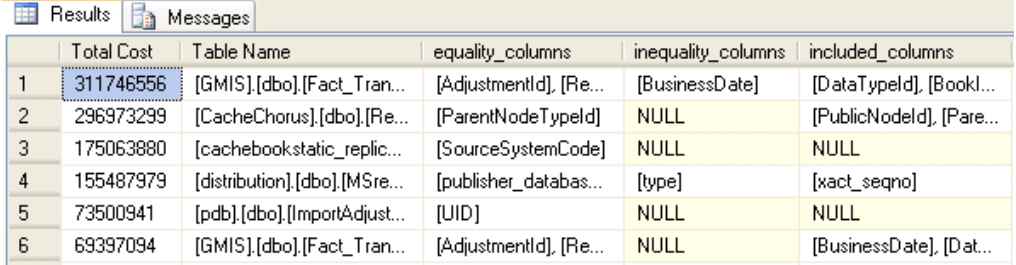
The measure of the importance of the missing indexes is given by the calculated column named Total Cost. This uses a combination of the impact of the index, its cost, together with a measure of the number and type of index accesses to calculate its importance. Running the script on my system produces the results given below:
Figure 1 Identify the missing indexes on your server, sorted by Total Cost. (click to enlarge)
The output shows the importance of the missing index (Total Cost), together with details of the underlying database, schema and table the index relates to (Table Name). Next, details of the columns in the identified table (Table name) required for a missing index are given, namely:
Having looked at how to extract these missing indexes, let’s now look how to implement them.
Which indexes to implement?Ok, if you’ve run the SQL given earlier, you’ll now have a list of indexes that might be worth implementing. So which indexes are actually worth implementing? It’s best not to blindly implement the suggested missing indexes, since indexes have a cost associated with them. When data is inserted into a table, data may also need to be added to any associated indexes, this can increase the query duration. That said, some indexes may improve the performance of updates/deletes since these queries often have a WHERE clause. You can use a stopwatch, DMVs or the Statistics Time (or IO) command to measure the impact of adding an index. I suggest you use these methods to determine the impact of an index before you implement it. Often, database systems have a bias towards either reporting or online transactional processing. Reporting systems typically involve a few long running queries, whereas transactional systems typically involve many queries running quickly. It is perhaps easier to add indexes to reporting systems where updates to tables/index are typically limited. As a general pointer, I tend to look firstly at missing indexes where only the equality_columns column contains a value. Next I will look at missing indexes where only the inequality_columns columns contain a value. I will next look at the other combination of columns. But as always, please ensure you test the impact of the new indexes on the performance of your queries. It is possible to amend the SQL in the script to restrict the output to only the database you are interested in by applying a WHERE clause. But remember it is worthwhile looking at all the databases on the server because other databases will use the server’s shared resources (for example, CPUs, memory, tempdb, and IO subsystem), and thus may impact the performance of your database. Ideally, you should have a test harness to record if your changes have resulted in a better query. Such a test harness would record the total duration of the query, how long it spends on the CPU or waiting on some resource, and much more… but that’s another article.
Conclusion DMVs provide a quick and easy way to investigate performance problems, such as identifying your missing indexes. There really are a great number of SQL Server secrets that DMVs can reveal. For further information, see my recent book “SQL Server DMVs in Action”, which contains more than 100 useful scripts:
Related articles:Identifying your slowest SQL queries SQL Server DMVs in Action (Book Review) <ASIN:1935182730> |
||||||||
| Last Updated ( Monday, 17 October 2011 ) |