| Automatically Generating Regular Expressions with Genetic Programming |
| Written by Nikos Vaggalis | |||
| Monday, 21 March 2016 | |||
|
Is it possible to "breed" a correct regular expression so that you don't have to go to the trouble of actually working it out for yourself? The answer seems to be "yes", and the result could even be better than the one you created by hard logical thinking.
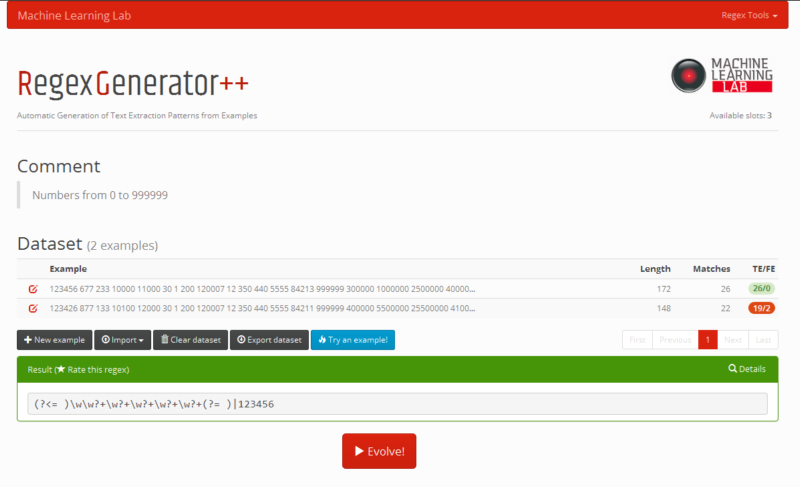
When you construct a computer program you do so through a series of well defined instructions that work on a set of data and produce a desired outcome. Given our focus here is on regular expressions, let's say that our goal is to match just the alphanumeric characters of the string: 'http://www.google.com'. Sticking to the traditional way we would have to supply an instruction in the form of a regular expression, that is '/[a-zA-Z]/g' But what if we could start the other way around? That is, get the computer to solve problems without being explicitly programmed? How can this be done? With Genetic Programming we can tell a computer program what we're after and let it generate a new program for us that will produce the same outcome as we had done it ourselves. This kind of code generation is a property of genetic programming. GP's roots are founded in the theory of biological evolution where a population is transformed into another population following the Darwinian principle of natural selection, using operations that are patterned after naturally occurring genetic operations, such as crossover and mutation. A population is comprised of individuals who are tested for their fitness, with those fittest being the ones to survive and produce offspring. The parallel with biology continues in that through the acts of mutation and interbreeding the population is evolved into a newer population that performs better than its ancestors. This evolutionary process runs continuously until a termination criterion is satisfied whereby the single best program in the population is harvested and designated as the result of the run. If the run is successful, the result may be a solution (or approximate solution) to the problem. GP could be considered as an offshoot of AI due to their similarities such as training algorithms with a dataset, but this view is starkly contradicted in "Seven Differences Between Genetic Programming and Other Approaches to Machine Learning and Artificial Intelligence" Moreover,it has been proven that results of genetic programms either outperform or directly compete with the human performance. So what has any of this to do with regular expressions ? 'Automatic Synthesis of Regular Expressions from Examples' is GP's application to regular expressions. It is a system that enables users to describe the task by singling out the text segments needed to be matched, and letting the code generation engine generate a suitable regular expression that can be then used in Java, PHP, Perl and so on. What's even more interesting is that using the system requires neither familiarity with GP nor with the regular expressions syntax. As a proof of concept, the researchers set up a publicly available web site called Regex Generator++ at http://regex.inginf.units.it/ For example given the text : "This is an IP address 192.168.4.1" highlighting 192.168.4.1 will generate an expression that matches text conforming to the pattern represented by 192.168.4.1 Of course the algorithm is as good as the size of the dataset trained with,so a larger dataset and more marked items to be matched increases the accuracy of the algorithm. The engine has been tested on extracting email addresses, IP addresses, MAC (Ethernet card-level) addresses, web URLs, HTML headings, Italian Social Security Numbers, phone numbers, HREF attributes, Twitter hashtags and citations, producing good results Of course, we couldn't resist putting it to the test ourselves as well, forcing the engine to come up with a regular expression able to match numbers between 0 and 999999. Therefore,we used the following text/data set (sample): 300000 1000000 2500000 400000000 22 0 1000 82468 73055 and then highlighted numbers 300000,22,0,1000,82468 and 73055 You can run a replay of the test yourself by grabbing the files used for this example, then importing them by pressing 'Import dataset' and/or 'Import result set' through the online form and finally pressing on 'Evolve!' to watch the engine go through the generation of candidate regexes until it finds the optimal one.
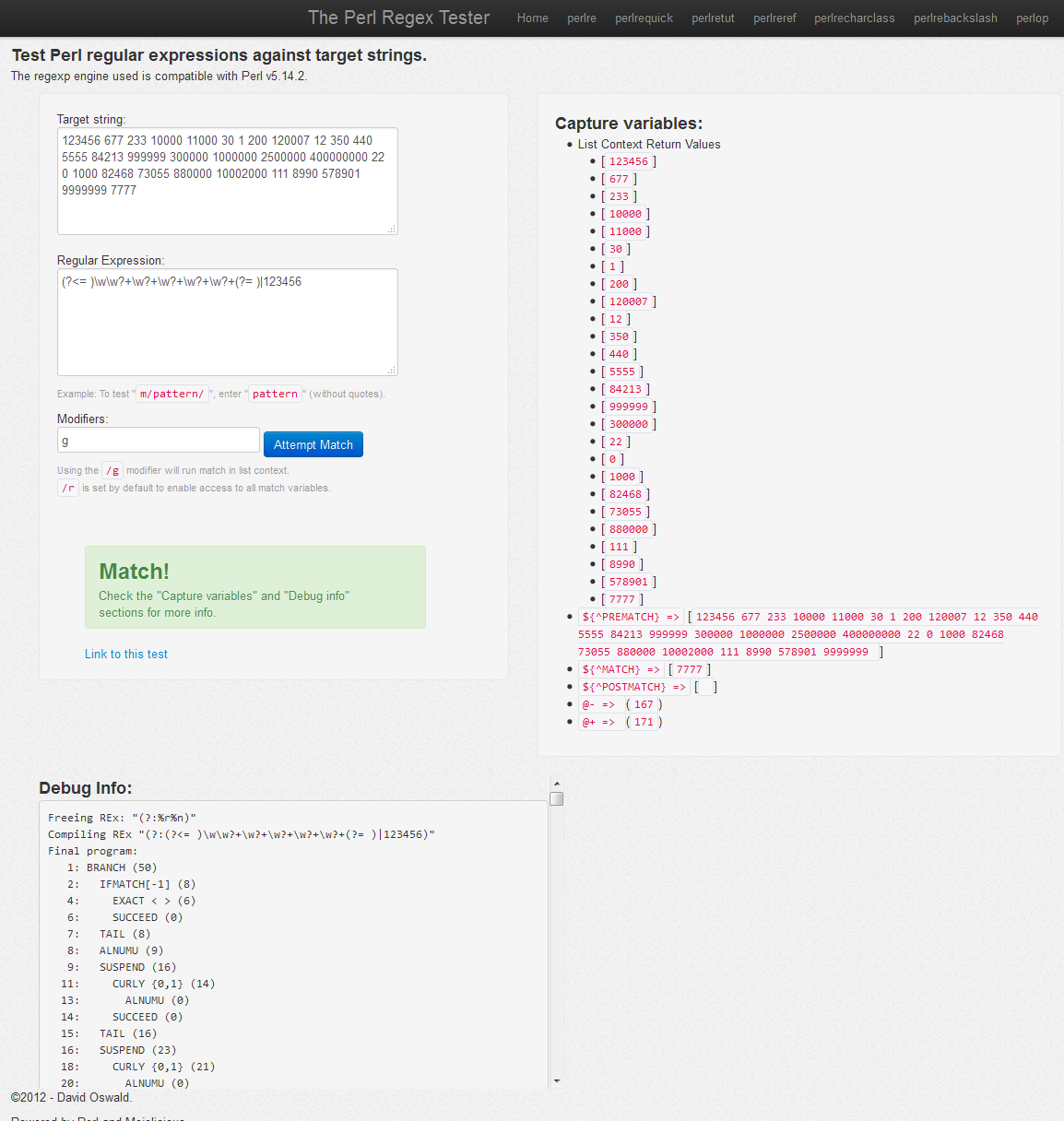
In this case the regex it came up with was,surprisingly: (?<= )\w\w?+\w?+\w?+\w?+\w?+(?= )|123456 We verified that it works by running it through the The Perl Regex Tester, (let's call it regex1)
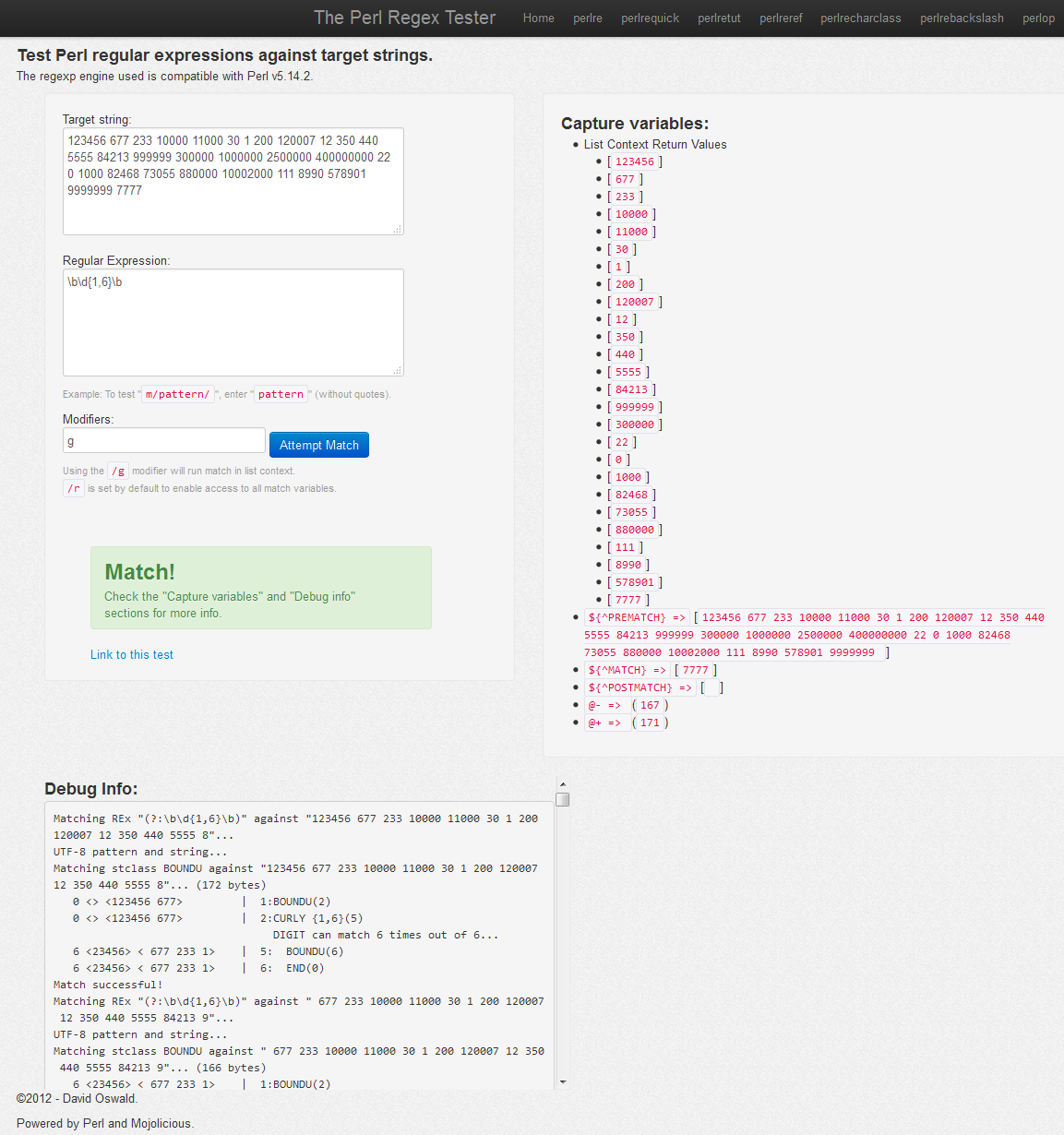
and compared it against the obvious (let's call it regex2): \b\d{1,6}\b
It looked unlikely, but both yielded the same exact results Moreover,running a benchmark on them, executing each of them continuously for 10 seconds, revealed that the humanly created regex2 is 3% (marginally) faster than the computer generated one: use Benchmark qw/cmpthese/; use Data::Dumper; my @set= qw (123456 677 233 10000 11000 30 1 200 So in this case the computer did not beat the human, let alone the unnecessary complexity of the generated regex, but it doesn't have to always be like that as in another case with a larger dataset, a bit more training and a random mutation,the outcome might be just surprising. There is a variety of reasons :
More InformationAutomatic Synthesis of Regular Expressions from Examples-Thesis Genetic Programming in the Trading market Related ArticlesGenetic Algorithms Reverse Resistance To Antibiotics Mechanical Insects Evolve The Ability To Fly Though A Window Introduction To The Genetic Algorithm The Virtual Evolution Of Walking
To be informed about new articles on I Programmer, sign up for our weekly newsletter,subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Monday, 21 March 2016 ) |