| A Programmers Guide To Interrupts |
| Written by Harry Fairhead | |||
| Friday, 29 April 2022 | |||
Page 1 of 2 The trick the computer uses in order to be so productive is to divide its attention between a number of tasks – and for this it uses interrupts. But what exactly is an interrupt and how should programmers think about this essentially hardware idea?
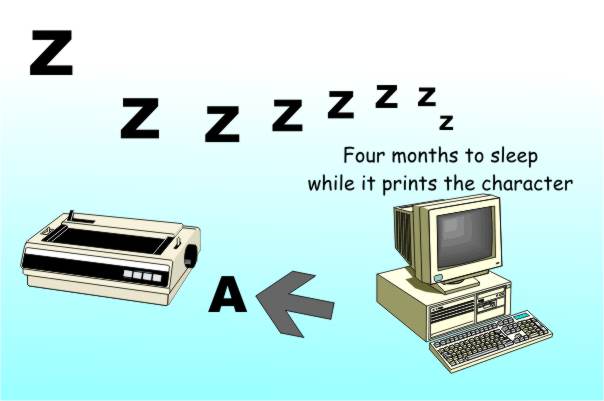
The computer is a very simple machine and yet it can do complicated things. This is a consequence of the fact that, even if you can only do something very simple, if you can do it fast enough then it can seem as complicated as you like! In the case of the digital computer the rate at which it can do simple things is so high that it can it to divide its attention between a number of tasks – like a juggler keeping a set of balls in the air. This is how it can run more than one program or indeed thread of execution apparently at the same time. For the moment forget any complications that having multiple processors or cores might bring into the discussion. Let's just assume that there is a single CPU processing all of the programs that you want to run. Long pausesBack in the early days of computing it was enough of a job to get the machine built at all without having to worry about how it could be used efficiently but as time went on it became clear that this was a real problem. You spend so much money on a computer, and in the early days it was a lot of money, and then it sits there not computing for most of its working life. There is a very real problem of getting all of the value out of your investment. For example, imagine what happens when it tries to print some letters on a old time printer - modern printers aren't much better but we don't use them as much. It takes, say, 0.1 of a second. The printer can print at 600 characters per minute so it’s very fast for a piece of hardware. But the computer is working with a clock cycle of say 100MHz (slow by today's standards), which means it can execute an instruction in 0.00000001s. (Making the unrealistic assumption that one clock pulse equals one instruction.) So in the time it has to wait for the printer to print another character, i.e. 0.1s, it could have performed 10 million instructions. If this doesn’t seem a waste to you then let’s stretch the time scale just a little. Suppose the new time scale is such that each beat of the machine’s clock is one second then in this new time scale the printer takes just short of 4 months to print a character. So in this sense the computer does one second’s work and then has 4 months off doing nothing at all... Let's update this to a 1GHz single core processor which would have performed 100 million instructions in the same time and has 40 months or over 3 years of its working life off just waiting for the printer.
Four months doing nothing after every character is printed – it’s a good life being a computer
Whenever a computer has to interact with the outside world, be it to read in data from a disk drive or write data to a printer or video screen, it generally has a long wait. In the early days the sense in trying to recover all that unused time was an economic imperative. The solution involved some software and some hardware. The software had to manage what the processor did while it was waiting; the hardware had to make sure that the processor knew when it was safe to go off and do something else. The details of the software take us into all of the ideas of the multi-tasking/multi-user operating system. The hardware, however, is worth looking at on its own. Hardware InterruptsIt is difficult to say who invented the interrupt because it’s one of those obvious things that really don’t need too much invention. (If anyone knows who, when and where the interrupt was invented please email me with the details.) The idea is simply that external hardware that operates at fantastically lower speeds than the electronics of the processor is provided with a connection – an interrupt line – that can be used to stop the processor doing whatever it is doing and get it to pay some attention to the needs of the peripheral. This might seem like the wrong way round from our first discussion of how everything works but it is much better to let the external hardware say when it needs attention than to say when it is busy. For example, the steps in sending some data to a printer would be:
This sounds all very easy but there are some really difficult problems in this sequence of actions which have taken many years to sort out. The key factor is that the processor has to be able to make a task switch, both when moving away from the printer routine aka the printer driver and when moving back to it in response to the interrupt. Task switching is difficult because you have to be able to guarantee that task one will not do anything to upset task two and vice versa. At the deepest hardware level this means that the processor’s registers have to be shared and so too does the main memory and every hardware device connected to it.
While waiting for an interrupt the machine can get on with something else!
I’ve Started So I’ll FinishLet’s start with the simplest part of the problem – the registers. Every processor has a set of registers that it uses to obey instructions. It is obvious that when a task switch occurs these registers have to be saved and then restored when the original task starts again. It is also clear that an interrupt can’t interrupt a processor in the middle of an instruction in such a way that the instruction cannot be restarted. To allow for all this the sequence of events is something like:
Notice that as the program counter is saved, task one restarts from exactly where it was and everything will work as before, as long as the interrupt routine doesn’t change any memory locations that task one is using or tries to use any hardware that task one is using. These last two conditions are fairly easy to ensure in small systems but they become increasingly difficult to deal with as the system becomes larger and there are more and varied tasks running. Where do you store the registers during a task swap? If you remember the Babbage’s Bag on stacks you will already have guessed that the system stack is the best place for them. It allows the machine to handle as many interrupts as you like and the RTIs all work correctly – just like subroutines. Indeed interrupt procedures are just like subroutines that are called when a piece of external hardware decides, rather than a natural result of the flow of control through a program. This point of view makes interrupts seem familiar and cosy but they aren’t and they contain some very nasty traps!

<ASIN:0789736136> <ASIN:158488360X>
|
|||
| Last Updated ( Friday, 29 April 2022 ) |