| Programmer's Introduction to XML |
| Written by Ian Elliot | ||||
| Thursday, 27 January 2022 | ||||
Page 1 of 3 XML is a general purpose markup language that can be used to control the structure of data. Despite the fact that many prefer the simplicity of JSON, it still has many advantages. What makes it so good?

XML is very similar to HTML and this is not surprising as they both stem from same base technology - SGML Standard Generalized Markup Language. XML was designed to be both human and machine readable and as a result it can be verbose and not as compact a way of packaging data as you might desire. It can also be criticized for being too much to type in but in most cases XML generation and consumption is done by programs with humans only getting involved when things go wrong. If you know HTML then you will certainly recognize XML. There is a sense in which XML is a general purpose version of HTML. You use HTML to markup web pages but you can use XML to markup and give structure to any data you care to think of. There was even an attempt to make HTML a subset of XML i.e. XHTML but this has been abandoned in favor of HTML5. Even though XML may not have taken over the data markup world as it was intended to it still has enough advantages to be preferred in many situations and this means that as a programmer you should know something about it. It does have a reputation for being difficult to process from scratch but the fact is that most languages have XML libraries that make working with it just a matter of making the right function calls. So let's see what it is all about.. Tags, nothing but tagsEXtensible Markup Language, to give XML its full title, is a way of indicating where different parts of a document start and end. For example, if you were keeping a list of your favorite books you might well use something like:
You are using the convention that a colon separates a “field name” that describes and identifies the data from the actual data. XML uses a different, but just as obvious, convention to do the same thing. It uses field names enclosed in “angle brackets”, or tags, and in this case the convention is that the actual data is between an opening and closing tag. If you know HTML this will seem obvious and as in the case of HTML5 XML's tags are to be interpreted as providing the semantic structure of the data. That is the tags tell you what the data is about not how it should be treated. Of course if you know what the data is about, its semantics, then what you do with it often follows immediately. For example, the same book data in XML would be something like:
You can see from this that to each opening tag there is a closing tag of the same name but starting with /. The beauty of this system is that the layout of the document doesn’t make any difference and data can include line breaks without any problem. For example, this version of the document means exactly the same thing as the previous one:
The whole point is that XML can represent the structure in the data without it having to be laid out in any particular way. For example, you could read the XML document out letter by letter over a phone connection and the person at the other end could write it down as one long string of text. It still means the same thing and the ability to “serialize” XML documents makes it possible to store them on disk or transfer them byte-by-byte, or even bit-by-bit, over a network without any special processing. NestingThings can be a little more interesting than the example above suggests because you can use tags within the content of other tags. In particular, to be strictly correct, the XML example given earlier needs an outer pair of tags that enclose everything. That is:
Notice that the indenting has been used to show clearly that all of the other tags are within the <Books></Books> pair. By now you already know that layout is irrelevant to the meaning of an XML document, but it helps to make it readable. An XML document always starts with tag that encloses everything – a so-called “top level” tag. You can repeat the “tag within tag” idea as often as you like and this one of the many things that makes XML powerful. It also makes XML look more complicated than it is. This nesting structure means that XML is capable of representing any data that forms a hierarchy or tree structure. Displaying XMLFor example a more complete record could be shown as:
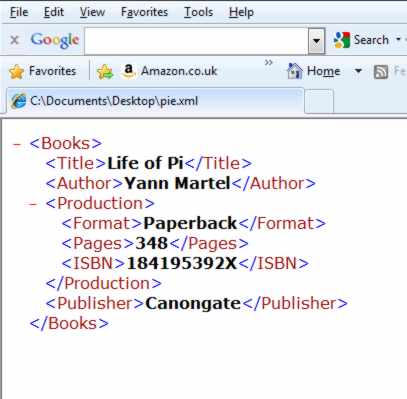
Although this looks much more complicated, you can see that it is just the basic principle of using opening and closing tags to enclose data or other tags. What might surprise you is that if you type this XML into a document and save it under a suitable name pie.xml say then you will be able to load it into a recent and view the structure of the data much more clearly. Web browsers will attempt to format any file ending in .xml with indenting and coloring to show the tags and structure. Figure 1 shows exactly what it looks like when loaded into Explorer.
Figure1: Viewing XML The power of XMLThere isn’t much more to XML than tags that surround data and you might well be thinking that this isn’t enough to warrant the fuss? However, you should be able to see that XML can be used to give structure to any data that you care to imagine. You are free to invent any tags that you need and use them to build structures that your data fits. The resulting XML file should be understandable by another human and, crucially, it should be processed correctly by any program that understands XML. For example, even though Internet Explorer had no prior knowledge of the structure of our book data record it managed to do a reasonable job of displaying it. It is worth saying that the majority of XML documents are likely to have been produced automatically by an application and consumed automatically by another application. XML may be human readable but that doesn’t mean that humans are always the source or the intended destination for XML documents. In most cases XML will lurk in the background, making some desirable facility work without you really being aware of why or how. |
||||
| Last Updated ( Friday, 28 January 2022 ) |