| How To Create Pragmatic, Lightweight Languages |
Page 2 of 3
In languages with strong regular expression capabilities such as Perl, this grammar could be defined, although tediously, in the host language itself, something often described as the "poor man's lexer":: https://www.perl.com/pub/regular-expressions/
We also set an associated rule which our identifiers should follow: this means that the following are considered valid identifiers in our language:
while the following are not:
There's a few more other things before we consider our grammar complete, like making the lexer context sensitive so that it can recognize that "\n" is significant only inside a String or enabling interpolation inside a String :
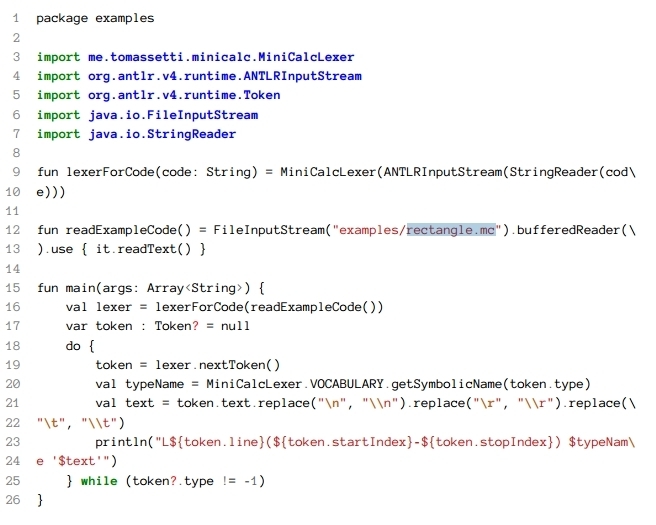
Now that our lexer grammar has been defined we need to invoke ANTLR through Kotlin code :
and invoke the lexer to print the list of tokens included in
We build and run the solution by running the "gradlew" wrapper from the CLI, something that produces the following output: which proves that our lexer functioned as expected and broke the text down to its tokens. In similar fashion, the chapter continuous with describing the lexer grammar for StaMac too. 5: Writing a parser builds on the work done by the lexer, with the Parser now having to arrange the tokens into an organized structure called a parse-tree. To get that tree we'll use ANTLR as a parser generator in accordance to out parser grammar. ANTLR version 4 in contrast to other recursive-descent parser generators, like Perl's famous Parse::RecDescent, is that it eliminates left recursion.For example if Parse::RecDescent would be fed with a left-recursive production, it would stall in an infinite loop. So the parser grammar in effect consumes the lexer grammar but also introduces the new notions, of statements, expressions, operations between expressions and precedance . Here is our parser grammar of our first example language, MiniCalc:
Line 4 options The approach adopted in going through the parser grammar remains the same as in the previous lexer grammar example - extracting blocks off the listing and going through them. For example : Labels are more useful when we have more than one terminal of the same kind in the same rule.This is for example the case in the binaryOperation alternative of the expression rule. You can see that we have two expressions: one with label left and one with label right. Later we will be able to ask for the left or the right expression of a binaryOperation avoiding every confusion. Then it's just a matter of invoking the parser with similar Kotlin code in order to get our parse tree. At this point we do have our first usable parser and, while not going behind the underlying theory of EBNF grammars, examining the listings of our toy grammars and their associated light explanations of their rules, allows us to deduct how simple lexer and parser grammars can be defined. So that's quite a few things already; defining a lexer grammar; building a lexer; defining a parser grammar; building a parser; combining the parser with the lexer and output a parse tree! And we're still on Chapter 5.
|
||||
| Last Updated ( Tuesday, 08 August 2017 ) |