| Audio Super Resolution |
| Written by Mike James |
| Thursday, 03 August 2017 |
|
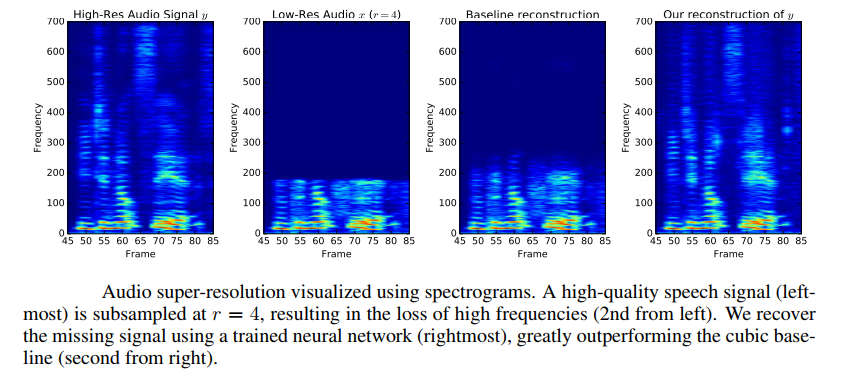
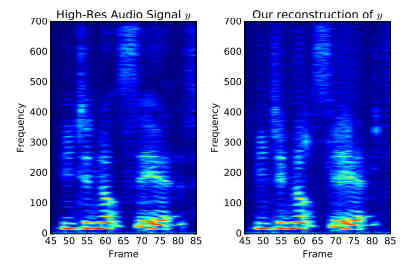
You may have heard of super seeing or super resolution implemented using a neural network. Convolutional neural networks were invented to tackle computer vision but what about sound? It turns out that a neural network can learn enough about sound to take a low resolution recording and turn it into hi fi. This is a really useful idea. Take a poor quality audio recording or live stream and process it to make it seem like a high quality one. This is the audio equivalent of up-scaling a video to make a low res video into, say, a 4K video. Neural networks have had a lot of success with upscaling and they seem to be able to infer missing information after learning how to upscale deliberately degraded images. Now the same ideas have been applied to audio. Volodymyr Kuleshov, S. Zayd Enam, and Stefano Ermon at Stanford have used neural networks to work directly with audio: In this paper, we explore new lightweight modeling algorithms for audio. In particular, we focus on a specific audio generation problem called bandwidth extension, in which the task is to reconstruct high-quality audio from a low-quality, down-sampled input containing only a small fraction (15- 50%) of the original samples. We introduce a new neural network-based technique for this problem that is inspired image super-resolution algorithms, which use machine learning techniques to interpolate a low-resolution image into a higher-resolution one. Learning-based methods often perform better in this context than general-purpose interpolation schemes such as splines because they leverage sophisticated domain-specific models of the appearance of natural signals. As in image super-resolution, our model is trained on pairs of low and high-quality samples; at testtime, it predicts the missing samples of a low-resolution input signal. Unlike recent neural networks for generating raw audio, our model is fully feedforward and can be run in real-time. In addition to having multiple practical applications, our method also suggests new ways to improve existing generative models of audio. You can see how well the method works by looking at spectrograms of the original, degraded, conventionally restored and then neural network upscaled audio:
You can see that there is much more going on in the higher frequencies in the neural network reconstructed audio. You can also listen to the results at: https://kuleshov.github.io/audio-super-res/. Another interesting feature is that the technique also "hallucinates" sounds that weren't there in the same way that visual neural networks do. Perhaps this too can be turned to creative uses. The code is available on GitHub and it makes use of TensorFlow. What sort of applications could this have? The authors suggest: Our technique extends previous work on image super-resolution to the audio domain; it outperforms previous bandwidth extension approaches on both speech and non-vocal music. Our approach is fast and simple to implement, and has applications in telephony, compression, and text-to-speech generation. The same architecture can be used on many time series tasks outside the audio domain. We have successfully used it to impute functional genomics data and denoise EEG recordings. Stay tuned for more updates!
More InformationAudio Super Resolution using Neural Networks https://github.com/kuleshov/audio-super-res Related ArticlesUsing Super Seeing To See Photosynthesis Computational Photography Shows Hi-Res Mars Seeing Buildings Shake With Software See Invisible Motion, Hear Silent Sounds Cool? Creepy? Extracting Audio By Watching A Potato Chip Packet Computer Model Explains High Blood Pressure Super Seeing Software Ready To Download Super Seeing - Eulerian Magnification
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Thursday, 03 August 2017 ) |