| DeepLoco Learns Not Only To Walk But To Kick A Ball |
| Written by Mike James | |||
| Thursday, 10 August 2017 | |||
|
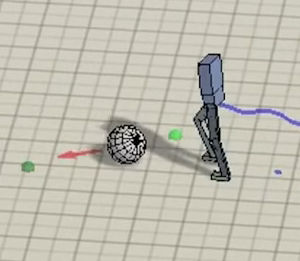
Learning to walk is hierarchical. or so DeepLoco seems to suggest. No this is not deep learning madness, but deep learning walking - and it looks good. The thing about the task of teaching a robot to walk is that it looks easy. You just achieve balance and then place one foot in front of the other. If you have ever seen almost any video of a robot actually trying to walk you might well decide that is is a much more difficult task than you first thought. DeepLoco, and yes I have to admit that too many things are called DeepSomething these days, is an attempt to learn to walk using a hierarchical approach. First a network learns a low-level control of the limbs to walk in a robust way. Next a higher-level network learns how to best use the lower-level abilities to navigate a terrain. It's a lot like how we do it - legs get on with the walking and we look out for the best way to go. The networks are trained using reinforcement learning. That is, the networks are not told how to walk, just how well they are doing. "Results are demonstrated on a simulated 3D biped. Low-level controllers are learned for a variety of motion styles and demonstrate robustness with respect to forcebased disturbances, terrain variations, and style interpolation. High-level controllers are demonstrated that are capable of following trails through terrains, dribbling a soccer ball towards a target location, and navigating through static or dynamic obstacles." The results, presented at SIGGRAPH 2017, are fairly impressive:
If you would like to see more details of how it all works then watch the full video:
It would be good to see this, or a similar algorithm, applied to a real robot. Simulations are fine, but the real world has a way of throwing the unexpected at would-be walkers. The research team has some ideas where to go next: "An interesting direction would be to learn adversarial and cooperative behaviors between multiple characters,such as for playing tag or for collision avoidance when crossing paths. In the future, we also hope to be able to directly learn to drive muscle-actuated 3D models." More InformationDeepLoco: Dynamic Locomotion Skills Using Hierarchical Deep Reinforcement Learning XUE BIN PENG and GLEN BERSETH, University of British Columbia KANGKANG YIN, National University of Singapore MICHIEL VAN DE PANNE, University of British Columbia Related ArticlesTo be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Thursday, 10 August 2017 ) |