| Transcription On Par With Human Accuracy |
| Written by Sue Gee |
| Tuesday, 29 August 2017 |
|
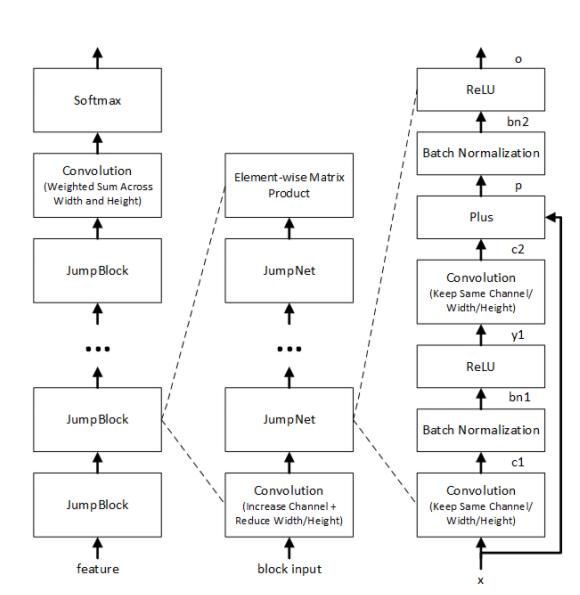
The Speech & Dialogue Research Group, part of Microsoft Artificial and Intelligence and Research have achieved a new conversational speech recognition milestone with word error rate reduced to 5.1 percent. We initially reported on the way in which Microsoft was applying deep neural networks to speech recognition six years ago and each successive year more progress is made towards the goal of having computers understand what people are saying and incorporating this ability in technologies such as Cortana, Sykpe Translator and other speech- and language-related cognitive services. Last year Xuedong Huang, Microsoft's chief speech scientist announced a major breakthrough - a speech recognition system that recognized words in a conversation with an error rate of 5.9 percent, that is the same or lower than that of human professional transcriptionists. This was an improvement on the 6.3% error rate from the previous month which was reported in The Microsoft 2016 Conversational Speech Recognition System. Now the team led by Huang has produced the The Microsoft 2017 Conversational Speech Recognition System which has details of the improvements made to claim a new record of 5.1% error rate, again with the Switchboard conversational speech transcription task, which has been used for more than 20 years to benchmark speech recognition systems. Switchboard is a corpus of recorded telephone conversation between strangers discussing topics such as sports and politics. Commenting on this year's advances Xuedong Huang on the Microsoft Research Blog states: We reduced our error rate by about 12 percent compared to last year’s accuracy level, using a series of improvements to our neural net-based acoustic and language models. We introduced an additional CNN-BLSTM (convolutional neural network combined with bidirectional long-short-term memory) model for improved acoustic modeling. Additionally, our approach to combine predictions from multiple acoustic models now does so at both the frame/senone and word levels. Moreover, we strengthened the recognizer’s language model by using the entire history of a dialog session to predict what is likely to come next, effectively allowing the model to adapt to the topic and local context of a conversation. Details are given in the newly published report which provides this schematic:
Huang attribute the recent success to being able to use Microsoft Cognitive Toolkit 2.1, which he describes as the "most scalable deep learning software available" and Azure GPUs, which helped to improve the effectiveness and speed for training models and testing new ideas. He points out that while reaching accuracy on par with humans has been a research goal for the last 25 years there is still more work for his group in teaching computers not just to transcribe the words spoken, but also to understand their meaning and intent, concluding: Moving from recognizing to understanding speech is the next major frontier for speech technology. More InformationMicrosoft researchers achieve new conversational speech recognition milestone The Microsoft 2017 Conversational Speech Recognition System Related ArticlesSpeech Recognition Breakthrough Microsoft Cognitive Toolkit Version 2.0 New Microsoft AI and Research Group To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Tuesday, 20 March 2018 ) |