| Capsule Nets - The New AI |
| Written by Mike James | |||
| Wednesday, 08 November 2017 | |||
|
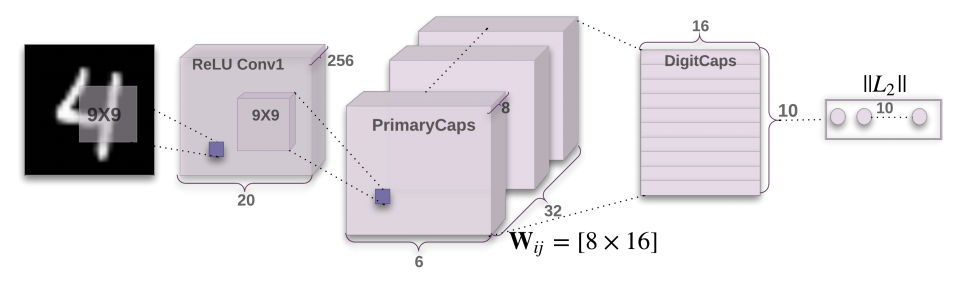
The amazing success of convolutional neural networks was the start of the new push to create AI. Now Geoffrey Hinton, Sara Sabour and Nicholas Frosst, members of Google’s Brain Team Toronto, have published results that reveal what might be an even better architecture - a Capsule Net. Neural networks have been around for a long time, but we couldn't make them work because we just didn't have the computing power and, as they didn't seem to work, there wasn't much enthusiasm for creating the sort of computing power they needed. The success of deep networks is very much because people like Hinton kept trying to find ways to make them work. Once you have a training algorithm for a multiple layer network - back propagation - the question is how should you organize the layers to make things work. The biggest problem is getting networks that take into account the invariances that are inherent in the data. For example, if you can recognize a cat in the middle of the image you can recognize a cat moved to the left, right or up and down. The neural network has to take into account the translational invariance of images. This is what the "convolutional" part of the neural network is all about. It applies the same smallish group of neurons with the same structure across the entire image. Of course the convolutional group isn't sensitive to cats but to lower level features such as lines and edges. The neurons in the next layer form higher level features from these and eventually we get to a cat sensitive neuron. Convolutional neural networks are automatically insensitive to translations, and hence you only have to train them with a picture of a cat centered in the image for them to recognize a cat in any position in the image. However convolutional networks do not automatically handle rotations and other distortions that result from shifting your viewpoint. If you want a neural network to recognize a cat rotated through an angle then you have to train it all over again on cat pictures at that angle. Of course, if you learn to recognize a new object you can recognize it rotated or scaled or from different viewpoints. You don't need to be shown thousands of images of it at different perspectives and angles. Clearly there is more going on here than a convolutional neural network and Hinton has commented that we need a new idea. In fact, he had the new idea some time ago, but only recently has it been possible to try it out. It is clear that neural networks are just a component in a bigger architecture. The human brain is not a single neural network it is a set of networks each doing something special. In years to come we will probably look back on this era of AI as the time we discovered the basic component and started to piece together the system using it. The problem with convolutional nets is that they throw away too much information. They recognize a face as a collection of two eyes, a mouth and a nose, but they don't keep the relationships between the parts. A capsule network is designed to build a parse tree of the scene that does keep the relationships between the different parts. This allows it to recognize an object that has been subjected to a transformation. The architecture is complex and uses a lot of neurons, but it only has two convolutional layers and one fully connected layer.
The Conv1 layer has 256 9x9 convolution kernels. The primary capsule layer consists of 32 capsules each one with 8 convolutional units with a 9x9 kernel. A big difference is that the capsules take the input from Conv1 as a vector and output a vector to the next layer. This generalizes the simple artificial neuron to a collection of neurons that do a lot more - it's a super vector-based neuron. It is as if a set of transistors had been put together to make a logic gate. There are lots of other fine details to ponder over in the paper, but the next question is how well does it work? The honest answer is that it isn't as good as the best convolutional neural network. It is as good as the first of their kind and, more importantly, it works better on transformed images. The test set was the MNIST set of handwritten digits and the error rate was 0.25% which is good for a three layer network. However, when the network was tested on the MNIST data set with small random affine transformations applied and the CapsNet achieved 79% accuracy where a traditional neural network achieved only 66%. Again good, but not necessarily good enough. There are all sorts of questions that need to be looked into and the paper states very clearly: "There are many possible ways to implement the general idea of capsules. The aim of this paper is not to explore this whole space but to simply show that one fairly straightforward implementation works well and that dynamic routing helps." This is a story worth keeping track of. "Research on capsules is now at a similar stage to research on recurrent neural networks for speech recognition at the beginning of this century. There are fundamental representational reasons for believing that it is a better approach but it probably requires a lot more small insights before it can out-perform a highly developed technology. The fact that a simple capsules system already gives unparalleled performance at segmenting overlapping digits is an early indication that capsules are a direction worth exploring." More InformationDynamic Routing Between Capsules Sara Sabour, Nicholas Frosst, Geoffrey E Hinton Related ArticlesGeoffrey Hinton Says AI Needs To Start Over AlphaGo Zero - From Nought To Top In 40 Days A Worm's Mind In An Arduino Body Google's DeepMind Learns To Play Arcade Games
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Wednesday, 08 November 2017 ) |