| Just Enough Error Correction |
| Written by Harry Fairhead | |||
| Friday, 17 February 2012 | |||
|
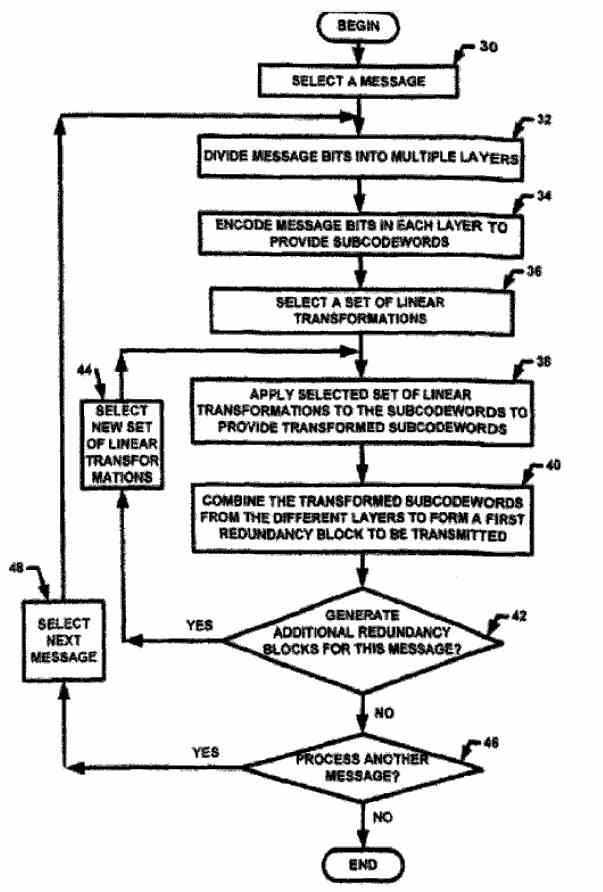
The trick with error correction is choosing the minimum number of bits to apply to provide accurate communication at the maximum rate possible. A new technique uses just as much error correction as needed has been granted a patent. Error correcting codes make it possible to send data over a noisy channel and recover it perfectly. The problem is that incorporating error correction means adding extra bits which reduces the ability of the channel to carry data. If you know that the channel is going to be noisy then pack in a lot of error correction and put up with not being able to send data as fast. The trick is choosing the number of error correction bits to apply to provide accurate communication at the maximum rate possible. Many systems in use today solve the problem of getting the error correction right by periodically testing the noise level on a channel and selecting a coding scheme to match. The problem with this is that many channels change their characteristics very quickly. For example, as you move around using a mobile phone the quality of reception varies and in principle you need to modify the code you are using every few seconds - which isn't particularly practical. Now a new technique has been invented by Gregory Wornell, a professor in the Department of Electrical Engineering and Computer Science at MIT, Uri Erez of Tel Aviv University in Israel and Mitchell Trott at Google. The idea is to create a single long error correcting code word but only send part of it. If the code word is received correctly then job is done and the data has been received. If not then the next part of the code word is sent and this provides error correction so that the incorrect first part, and any errors in the second part can be corrected and the data received. If this doesn't work then another part of the code can be sent and so on until the data is received correctly. You can see that this scheme depends on being able to construct a code that can be used in this "chunk at a time" way. The chunks are sent one after another until the receiver signals back to the transmitter to stop. This scheme is close to optimal, even if the quality of the channel varies during the transmission. Just enough bits are sent to get the message through given the prevailing noise levels. The clever part is the block coding. The way that this works is that first the message is split into blocks of equal size. These are coded using a standard error correcting code. Then the code words are combined by being multiplied by different constants and added together. This is the first chunk of the final code. The subsequent chunks are generated by multiplying by different constants and summing. Decoding depends on knowing the size of the initial blocks and the multipliers used. It is supposed that an optimal choice can be found to standardize these parameters. The computational load of decoding depends on the number of blocks that are combined.
A paper in IEEE Transactions on Information Theory describes the coding and decoding in enough detail for it to be clear that it is a practical scheme. The inventors have also been granted a patent, which is something of a shame for any programmer wanting to make general use of the technique. However, in this case at least, we can say that the patent is on something that is probably worth patenting and not just a slightly different design of click button or widget. More InformationU. Erez, M. D. Trott, and G. W. Wornell, "Rateless Coding for Gaussian Channels", IEEE Trans. Inform. Theory, vol. 58, no. 2, pp. 530-547, Feb. 2012. Further reading
Comments
or email your comment to: comments@i-programmer.info
To be informed about new articles on I Programmer, subscribe to the RSS feed, follow us on Google+, Twitter, Linkedin or Facebook or sign up for our weekly newsletter.

|
|||
| Last Updated ( Friday, 17 February 2012 ) |