| Apache Fluo Improves Spark Integration |
| Written by Kay Ewbank | |||
| Friday, 07 July 2017 | |||
|
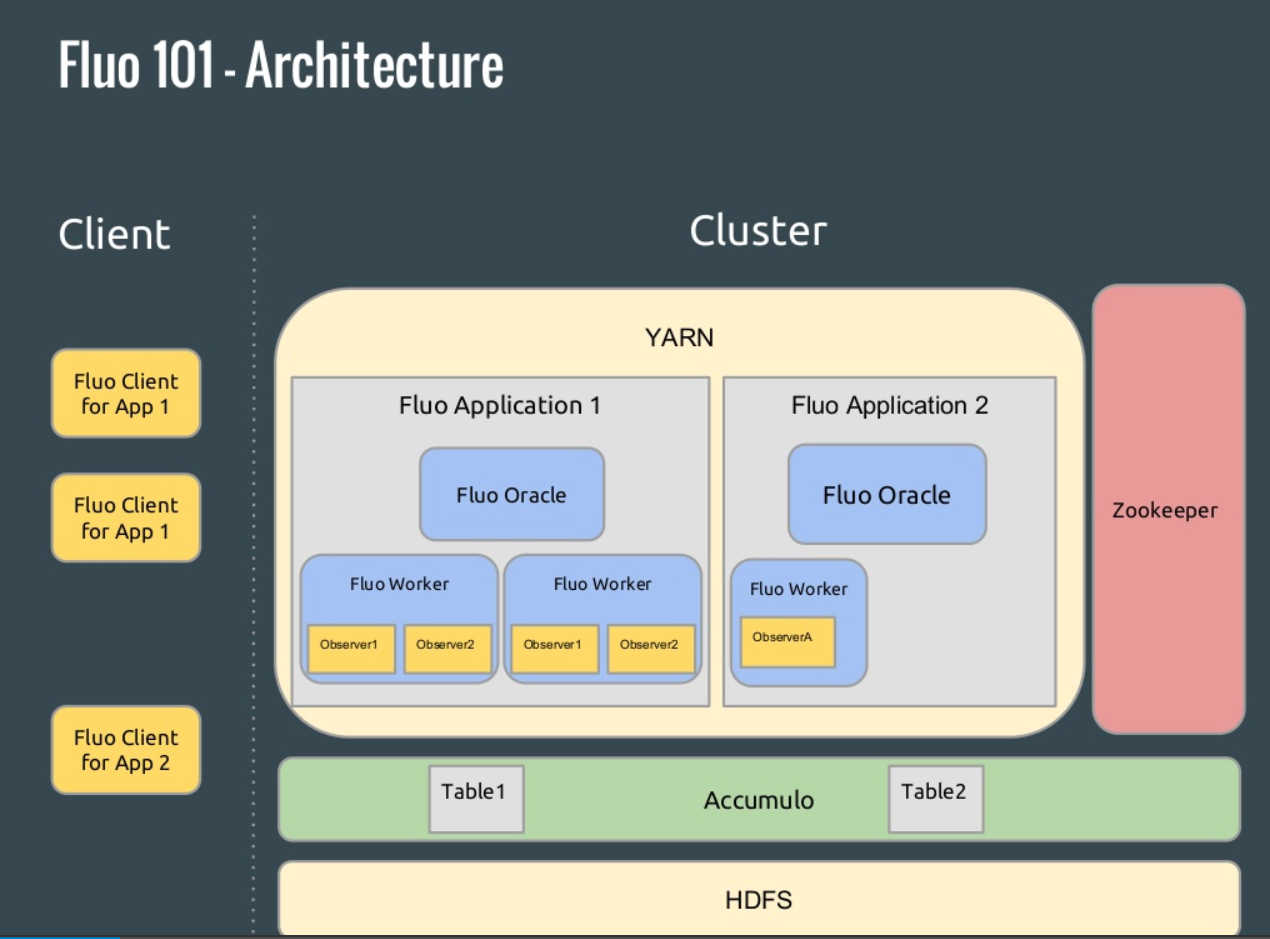
There's a new version of Apache Fluo. Fluo is an implementation of Google's Percolator for Apache Accumulo. Version 1.1.0 of Apache Fluo (incubating) improves scalability and Spark integration. It also has a new Observers API. Fluo is an open source implementation of Percolator (which populates Google's search index). Fluo makes it possible to update the results of a large-scale computation, index, or analytic as new data is discovered. The problem Fluo and Percolator were designed for is that caused by the need to have an up-to-date index of the web when new documents are continually arriving. Google's indexing system stores tens of petabytes of data and processes billions of updates per day on thousands of machines. MapReduce and other batch-processing systems rely on creating large batches for efficiency so can't cope with the need to carry out so many small updates, while databases can't handle the storage and throughput requirements. Percolator was designed to meet this need. It incrementally processes updates to a large data set, and is used to create the Google web search index. Google says that by replacing a batch-based indexing system with an indexing system based on incremental processing using Percolator, they can process the same number of documents per day, while reducing the average age of documents in Google search results by 50%. Fluo provides an open source version of Percolator that works with Apache Accumulo. Accumulo is a sorted, distributed key/value store that offers a robust, scalable, high performance data storage and retrieval system. It is based on Google's BigTable design and is built on top of Apache Hadoop, Zookeeper, and Thrift. The architecture of Fluo can be seen in the slide below from the Accumulo Summit:
The improvements to the latest version of Fluo start with a better API for providing Observers. The previous version required configuring an Observer class for each observed column. It was cumbersome to use and made using lambdas impossible. The new API only requires configuring a single class that provides all Observers. This single class can register lambdas to observe a column. Scalability is another area to be improved. In the previous release each worker scanned the entire table looking for notifications that hashed to it. In the new version workers divide themselves into groups and each group scans a subset of the table for notifications. Every worker in a group scans the group's entire subset of a table looking for notifications that hash to it. The final improvement is better Spark integration. Apache Spark can be used to preprocess and load batches of data into Fluo, but in the previous release it was difficult to pass FluoConfiguration objects to remote Spark processes. The current version has serializable FluoConfiguration making this task easier. More InformationTips For Writing Fluo Apps From Accumulo Summit Related ArticlesApache Kudu Improves Web Interface Apache Spark MapR Connector Provides JSON Support Apache Arrow Adds Streaming Binary Format To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 07 July 2017 ) |