| Pachyderm Gets Faster And Gets Funding |
| Written by Kay Ewbank |
| Wednesday, 21 November 2018 |
|
Data lake company Pachyderm has announced a new version of its software, along with $10 million in funding for future development. The developers say the new version of Pachyderm has more than a thousand times increase in workload performance, enabling 100s of terabytes of data to be processed per job. Pachyderm is a storage and analytics engine that sits in a similar area of use to tools such as MapReduce. Pachyderm lets you chain together data into data pipelines, to carry out operations such as data scraping, ingestion, cleaning, processing, modeling, and analysis. You just declaratively tell Pachyderm what you want to run, and Pachyderm takes care of triggering, data sharding, parallelism, and resource management on the backend.
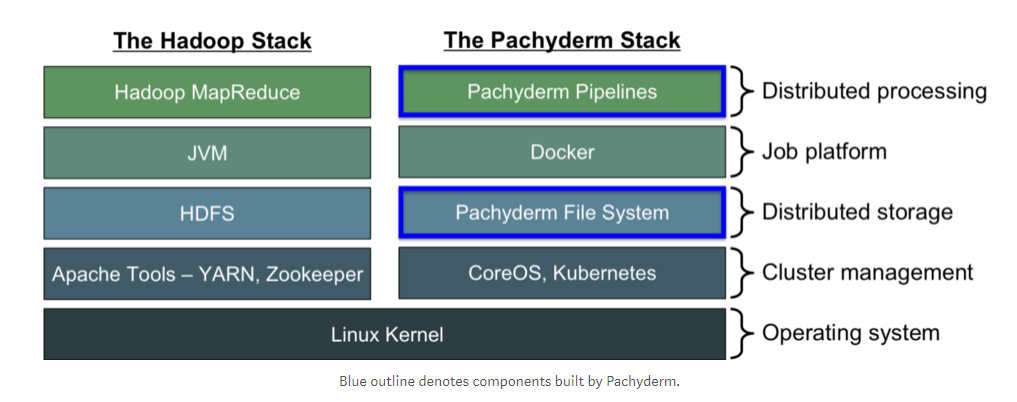
It packages everything up in containers, and has built-in dependency management and collaboration primitives. It uses well-established open-source products including Docker and Kubernetes so the developers are able to focus on just the analytics platform. This means that users can use whatever languages or libraries their pipeline needs. Pachyderm also has options for carrying out version control on data, so the system can show how data has changed. Pachyderm also tracks where data comes from, and can carry out incremental processing: to only process new data. The developers say one of the system's main strengths is the use it makes of well established open-source products to create a full stack of tools for data storage and analysis.
The improvements to the new release of Pachyderm are mainly in performance. The developers have reworked how versioning metadata is stored and tracked, and this means for some workloads there is a more than one thousand times improvement in performance and scalability. The improvements were driven by bottlenecks experienced in scaling by customers using the previous version of Pachyderm. To overcome these, Pachyderm’s storage layer (PFS) was changed to be smarter in the batching together of writes to object storage to reduce latency and improve performance. The format of the metadata was also redesigned to support external sorting of the hashtrees used to take snapshots of the filesystem. Other improvements include better support for SQL and CSV data so that there's less manipulation for distributed processing, and expanded Auth & SSO support to control who has access to specific data. This feature makes use of Okta, and the enterprise version can use both GitHub and Okta for Auth and controlling user access within the system.
More InformationRelated ArticlesHadoop 3 Adds HDFS Erasure Coding Hadoop 2.9 Adds Resource Estimator Hadoop SQL Query Engine Launched
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |