| Apache Kylin Adds Real-time OLAP |
| Written by Kay Ewbank | |||
| Friday, 03 January 2020 | |||
|
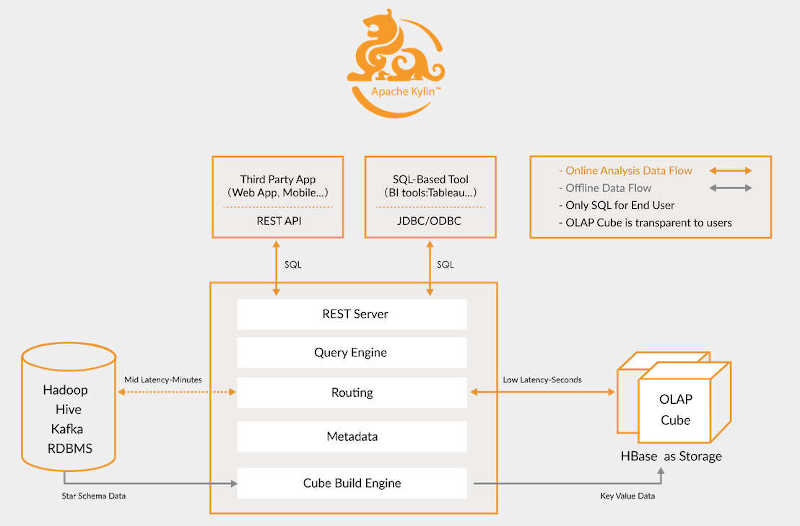
Kylin 3.0 has been released by Apache with improvements including support for real-time OLAP, integration with Apache Livy, and a curator-based job scheduler. Kylin is an open source distributed analytics engine designed to provide a SQL interface and multi-dimensional analysis (OLAP) on Apache. It was originally developed at eBay before becoming an Apache project. The Kylin OLAP Engine is made up of a metadata engine, a query engine, a job engine and a storage engine. It also includes a REST Server to service client requests. The query engine is based on Apache Calcite.
While previous releases of Kylin had OLAP support, the main improvement to the new release is the ability for Kylin to implement a millisecond-level data preparation delay for streaming data from sources like Apache Kafka. This means Kylin can now support sub-second level OLAP over historical batch data, near real-time streaming as well as real-time streaming. The Kylin team says this means you can now use one OLAP platform to serve different scenarios. The new functionality comes from the newly introduced Kylin real-time receiver and coordinator components.
The second improvement of note is the ability to submit Spark jobs via Apache Livy. Livy is an Apache incubating project that provides a service that can be used to interact with a Spark cluster over a REST interface. It lets you submit programmatic, fault-tolerant, multi-tenant Spark jobs from web and mobile apps with no Spark client needed. This means multiple users can interact with your Spark cluster concurrently and reliably. The new support in Kylin means an administrator can configure Kylin to integrate with Livy for Spark job submissions. The Spark job is submitted to the Livy Server through Livy’s REST API, instead of starting the Spark Driver process locally. This enables the management and monitoring of the Spark resources, and also releases the pressure of the nodes where the Kylin job server is running. The final major improvement is the addition of a curator-based job scheduler. This automatically discovers the Kylin nodes and will do an automatic leader selection among them to choose the node that will submit jobs. The Kylin team says that with this feature, you can easily deploy and scale out Kylin nodes without manually updating the node address in kylin properties and having to restart Kylin to make the change effective. Kylin 3 is available for download from the Kylin website.
More InformationRelated ArticlesApache Kylin 2.5 Adds All-in-Spark Cubing Engine Kylin 2.3.0 Adds SQL Server Support Apache Kylin Gets Table Level ACL Management Apache Kylin Adds RDBMS Support Spark BI Gets Fine Grain Security
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 03 January 2020 ) |