| MapR-DB Adds Native Secondary Indexes |
| Written by Kay Ewbank | |||
| Thursday, 12 October 2017 | |||
|
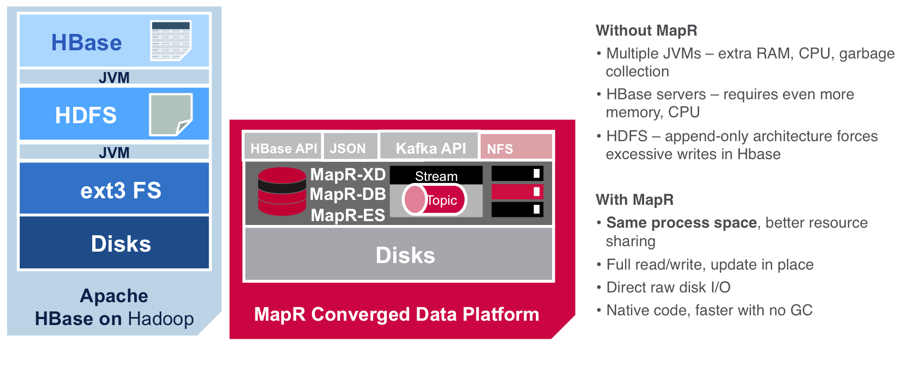
There's a new release of the MapR database, MapR-DB. Version 6 adds native secondary indexes and improved OJAI APIs. MapR is best known for its data platform that provides access to a variety of big data sources including Apache Hadoop and Apache Spark. MapR-DB is its built-in database designed to work with data-intensive applications that spread across local networks, edge and the cloud.
The new release adds a number of extras, and also performs better. The first improvement is support for native secondary indexes. Until now, MapR-DB only used rowkey indexes for optimizing access. The new built-in secondary indexes can be used to query any columns in the DB tables. You can set up native secondary indexes for MapR-DB JSON tables, and make use of auto-propagation, auto-scale & auto-management of the indexes. You can also create composite indexes on multiple columns, use all data types, and set up hashed indexes. The queries can make use of both primary and secondary index tables. The next improvement is improved support for MapR-DB OJAI 2.0 APIs. OJAI (Open JSON Application Interface) has been improved to add better support for JSCON grammar, and a new OJAI query interface. You can now use conditional filtering and sorting, along with what the developers describe as: "smart query execution to support operational and operational analytic applications on any data scale and with any query complexity" Another useful improvement is better support for Apache Drill. This provides SQL analytics on the data in MapR-DB JSON tables. Drill is a distributed SQL query engine and serves as a unified interactive access layer for the MapR platform bringing together data from MapR-FS and MapR-DB. The improvements mean ad-hoc SQL queries on MapR-DB are faster because Drill SQL queries can make use of the new MapR-DB secondary indexes, including the ability to use filter, sort, offset and limit operators. MapR-DB JSON tables are also more closely integrated with Apache Spark, and this can be used to build and serve machine learning models on MapR-DB tables directly. The integration in this version has added native Spark connectivity, with support for all key Spark constructs - RDDs, Dataframes/Datasets. Apache Hive support has also been improved, with a new Hive storage handler for MapR-DB JSON tables.
More InformationRelated Articles
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |