| Query Unicode From The Command Line |
| Written by Nikos Vaggalis | |||
| Tuesday, 28 January 2020 | |||
|
uni is an open source tool with just four commands that lets you query the Unicode database from the command line. It will make you wonder how you went through life dealing with character encodings without it. With this tool you get to interrogate the Unicode database (full support for Unicode 12.1) from the CLI. For example,working with HTML and want to find the html escape of the € euro sign? Tell uni to identify it:
or, have no clue what the euro sign looks like? uni can work the reverse too:
But why is having access to Unicode from the CLI an advantage? As with everything, having the CLI at your disposal to do CLI-based operations is indispensable. For starters you can automate and write programs fed from stdin with uni:
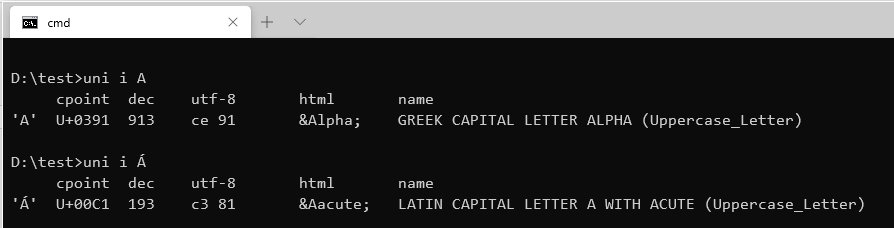
Furthermore, you don't have to waste time traversing web pages in order to look up code points, representations and other character set information like I did when doing fine-grained "forensics" trying to debug some CGI scripts messed up by a UTF8-related issue. As documented in Perl Unicode Forensics: The issue was that the same CGI script produced different results when run under different servers. In the first case the Greek characters sent by the client and consumed by the server are getting into the database as they should do, while in the second case the very same data under the same workflow ends up as "garbage".That is, for example, Greek character capital A, or alpha, ends up as sequence "Γ\201". Trying to distinguish Greek Alpha from Latin A, I had to go back and forth the Latin1/iso-8859-1 and Greek/iso-8859-7 tables to look up the relevant information. With uni I could just have typed:
It's magic. Furthermore I had to look up the same characters on the UTF8 table too in order to get their byte representation back. Well,uni would had already taken care of that in the step above, saving my time and sanity. But uni goes one step further; it can work with emojis too! > uni e cry
It includes many other features and integrations which you check on its Github repo page. It also comes in source or pre-built binaries for many platforms, especially useful when on Windows. For a better experience on that platform make the switch to the new Windows terminal. For more insight on how Windows and the console handles matters check Unicode issues in Perl. To wrap it up, if you deal with Unicode make sure to give uni a try. It will become your best buddy. More InformationRelated Articles
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Tuesday, 28 January 2020 ) |