| Regexploit - Put A Stop To Regular Expression DoS Attacks |
| Written by Nikos Vaggalis |
| Monday, 29 March 2021 |
|
There's a new tool that can identify resource-hungry regular expressions that can be potentially exploited in launching ReDos attacks. In Can Regular Expressions Be Safely Reused Across Languages? I looked into whether it is possible to reuse a regular expression crafted in JavaScript verbatim in Python. Would doing so lead to the same results and performance? Swap your languages of interest in place of JavaScript and Python; the question remains the same. Setting aside the question of equality of the cross-language results, the article also looked at the performance side of the story which perfectly relates to this Regxploit tale. The findings on the performance side were that: Due to differences in the underlying algorithms which the regex engines are based on, a match in some languages may require greater than linear time (polynomial or exponential in the worst case) in the length of the regex and the input string. These are called super-linear matches and some regex engines fall prey to this super-linear behavior while the wiser ones avoid it. Thus regexes that fall into this super-linear category can be exploited by being fed specially crafted strings which would subsequently overload the host, i.e. web server, as in a DoS attack, eventually bringing it down to its knees. So what can you do about it? Of course, craft your regexes correctly. However the problem is that by their very nature they're already so dense that they can't be adequately tested, plus the testing itself depends on the input data, which means that it could be data in a format that you hadn't predicted, one that causes the damage.
Another option, as revealed in "Can Regular Expressions Be Safely Reused Across Languages?", is to opt for Perl or PHP: In our experiments, exponential behavior was unusual in PHP and Perl, while it occurs at about the same rates in Java, JavaScript, Python, and Ruby. Similarly, PHP and Perl have a lower incidence of polynomial behavior than do the other Spencer engines. The differences between these two families can be attributed to a mix of defenses and optimizations. So it seems that PHP and Perl, PHP probably because it utilizes the PCRE (Perl Compatible Regular Expressions) library, were the only ones that had explicit defenses against exponential time behavior. Read that article to form a complete picture.
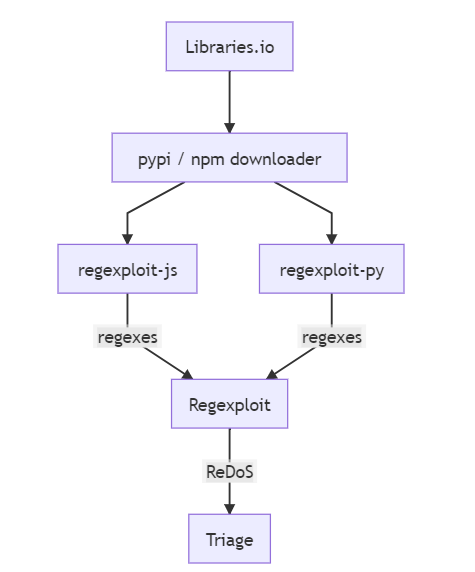
If you're not using one of those languages, or you don't want to depend on their runtime mechanisms for safeguarding but want to get to the source of the problem as soon as possible, then you can go for Regexploit, a tool that scans your code in order to locate those vulnerable regular expressions. You enter regexes via stdin or through a file and Regexploit walks them through trying to find ambiguities and ways to make the regular expression not match, so that the regex engine has to backtrack. If the regex looks OK it will say “No ReDoS found”. The tool has built-in support for extracting regexes from Python, JavaScript, TypeScript, C#, JSON and YAML but: If you are able to extract regexes from other languages, they can be piped in and analysed. Does it mean that it can work with any regex piped into it? That claim of uniformity reminds me of the very issue that "Can Regular Expressions Be Safely Reused Across Languages?" set out to discover. So I'll rephrase: "Can Regexploit Be Safely Reused Across Languages?" Does it support all regex dialects? For that I have to ask the makers. Doyensec. The tool was also used to analyze the top few thousand npm and pypi libraries (that is Javascript and Python dialects) grabbed from libraries.io. It found that the most problematic area was the use of regexes to parse programming or markup languages.I guess that for some things you should not use regular expressions, like parsing HTML. See You can't parse [X]HTML with regex. Better leave that job to dedicated parsers.That aside, the next problematic area found was the mishandling of optional whitespace. Installation is as simple as:
and can be invoked with passing it a regular expression on the stdin or pipe in a file:
As already said, there is built-in support for parsing regexes out of Python, JavaScript, TypeScript, C#, YAML and JSON, but to extract regexes from JavaScript / TypeScript code, NodeJS 12+ is also required. So could Regexploit become part of your arsenal, if not completely replace it, against ReDoS? As the tool only supports NFA regex engines, there's just one extrayou need - use DFA like Go does and be completely safe. More InformationRegexploit: DoS-able Regular Expressions Related ArticlesCan Regular Expressions Be Safely Reused Across Languages? Advanced Perl Regular Expressions - The Pattern Code Expression Advanced Perl Regular Expressions - Extended Constructs
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Monday, 29 March 2021 ) |