| Can Regular Expressions Be Safely Reused Across Languages? |
| Written by Nikos Vaggalis | |||
| Monday, 02 September 2019 | |||
Page 1 of 2 That is, can I reuse a regular expression crafted in JavaScript verbatim in Python? In doing so, will I get the same results and performance? Enter your languages of interest in place of JavaScript and Python, the question remains the same. It is a not well kept secret that programmers are huge fans of copying and pasting code snippets, regular expressions included, that are freely available across the web. But unlike copying and pasting code within the boundaries of the same programming language, does copying a regular expression that was crafted in one language into another work as assumed, or would it introduce errors, both semantically and in performance? "Why Aren’t Regular Expressions a Lingua Franca? An Empirical Study on the Re-use and Portability of Regular Expressions", a paper presented at the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE ’19), attempts to shed light on the question: are regular expressions truly portable? But first things first. Do programmers engage in copying and re-using regular expressions to begin with? Really, DO they? To find out, the researchers from Virginia Tech, James C. Davis, Louis G. Michael IV, Christy A. Coghlan, Francisco Servant and Dongyoon Lee, surveyed 159 professional developers on the job in order to understand their perceptions and practices around regular expressions.The findings leave no room for misinterpretation: 94 percent of these developers copy and reuse regex constructs taken from Stack Overflow and other forums and 47% think that they are indeed portable across language barriers. These findings firmly confirmed the researchers' beliefs that this is a real issue that has to be further investigated and get to the bottom of it. So the next stage was to measure the extent of that reuse:
and
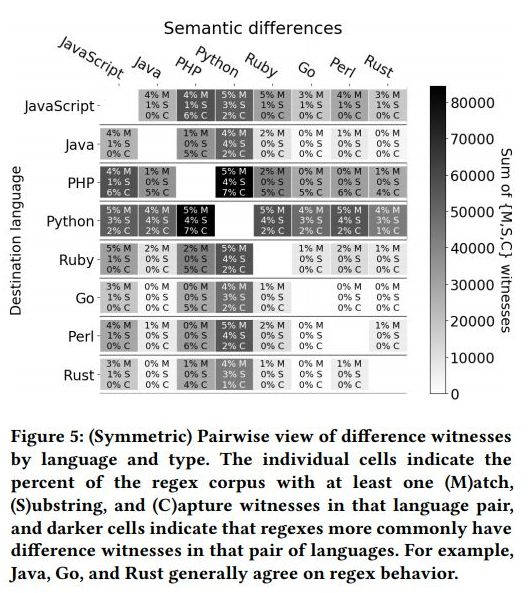
To answer them, they built a regex corpus consisting of 537,806 regexes extracted from 193,524 libraries/modules written in The findings of this experiment showed that thousands of modules (20%) shared the same regexes, both within and across languages and that 5% of all corpus modules (about 10,000) primarily written in JavaScript, use regexes from Stack Overflow and RegExLib. Based on their polyglot regex corpus, they then explored the issues of portability, starting out with the semantic portability defined as the case when two languages exhibit different features (or behaviors) for the same regex syntax. To do that they ran a large set of randomly generated inputs against a large set of complex regular expressions in each language that supported them.This resulted in the so-called "Witness points" which were used as the basis of comparison among all the languages grouped by every possible pair.The comparison's outcome was plotted into a chart categorized by Witness type in order to highlight the differences. These categories were: (1) Match witness: Languages disagree on whether there is a match (2) Substring witness: Languages agree that there is a match but disagree about the matching substring (3) Capture witness: Languages agree on the match and the matching substring, but disagree about the division of the substring into any capture groups of the regex
From this chart you can find out the incompatibilities across language pairs.Going through it, for example, reveals that JavaScript and Java have a 4% deviation on the Match witness scale and 1% on the Substring witness scale. Another take is that PHP and Python seem to disagree on pretty much everything; 5% deviation on Match, 4% on Substring and 7% on Capture. The research now turns to the causes of this behavior. Apparently:
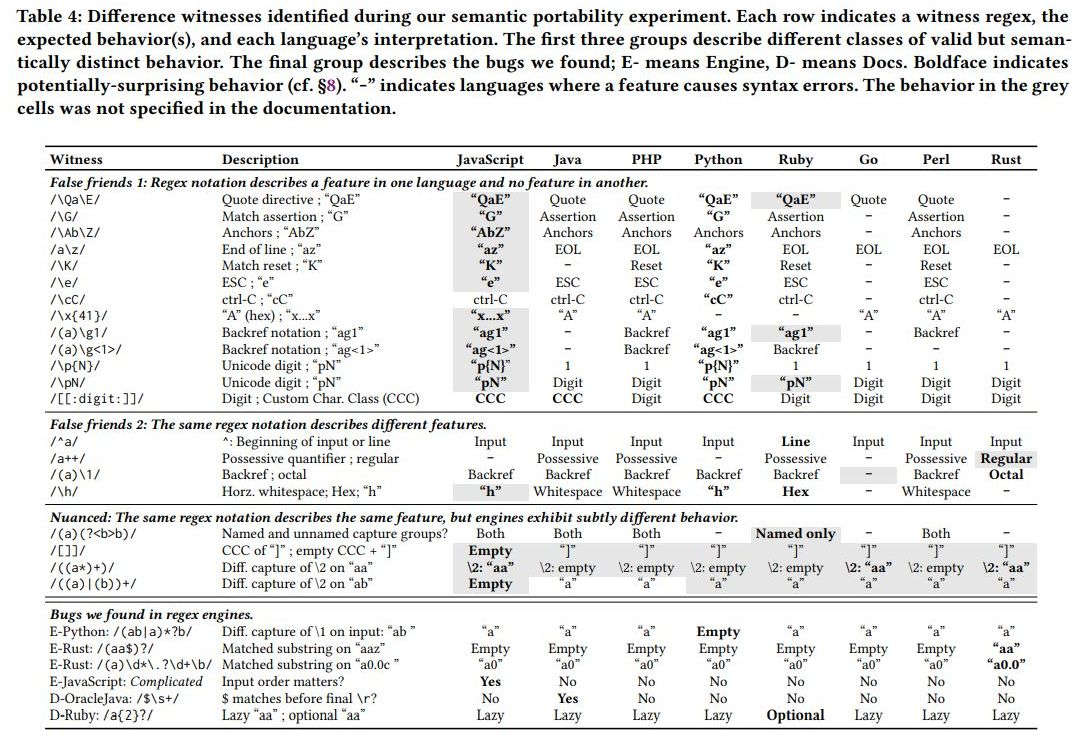
The new findings were summarized in the following table:
From this chart we can derive that for example in JavaScript the anchor notation /\Ab\Z/ is interpreted literally as AbZ, despite that developers who use this notation probably intend anchors, or that /^a/ in most languages means match at the beginning of input but in Ruby means match at the beginning of the line.In summary 15% of regexes exhibit documented and undocumented semantic differences. But the findings don't stop here;the researchers even identified bugs in the regex engines of V8-JavaScript, Python, and Rust, to which official bug reports were filed. Yet another conclusion is that these unusual behaviors could not be explained by peeking into each language’s regex documentation, as such "testing, not reading the manual, is the only way for developers to learn these behaviors". |
|||
| Last Updated ( Tuesday, 03 September 2019 ) |