| Scrape The Web With Crawlee |
| Written by Nikos Vaggalis | |||
| Tuesday, 18 October 2022 | |||
|
Crawlee is an open source web scraping and browser automation library for Node.js designed for productivity. Made by Apify, the popular web scraping and automation platform.
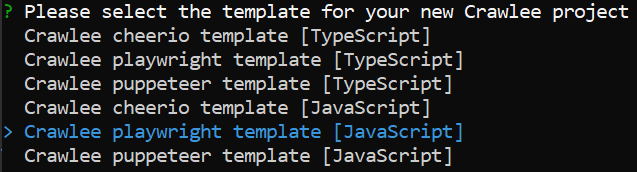
Crawlee is the successor to Apify SDK and escaped Apify's labs after 4 years in development. While the Apify SDK was always open source, the library's name caused users to think its features were restricted to the Apify platform, which was not true. For that reason, the Apify SDK was split into two libraries, Crawlee and Apify SDK. Crawlee will retain all the crawling and scraping-related tools, while at the same time, Apify SDK will continue to exist but keep only the Apify-specific features. They've really put a lot of work into making it a customizable library. For instance you can start with simple HTTP-based scraping, but switch to browser-based automation by calling Playwright or Puppeteer under the covers or set your proxies to avoid getting blocked by using auto-generated human-like fingerprints, headless browsers, and smart proxy rotation. Crawlee's features - Single interface for HTTP and headless browser crawling HTTP crawling - Zero config HTTP2 support, even for proxies Real browser crawling - JavaScript rendering and screenshots If you have Node.js installed, you can try Crawlee by running the command below and choose one of the available templates for your crawler.
Then choose from the drop down list of either Typescript or Javascript templates and hit enter on the one that you like.
After that it's going to automatically generate some boilerplate code and also install all the dependencies that you need to get started. After the install is done, then if you cd into your new project's folder you'll notice that there are already a bunch of files there; a docker file, a package.json, and a ts config file if you're using Typescript. Do
and you're good to go. Crawlee is open-source and runs anywhere, but since it's developed by Apify, it's easy to set up on the Apify platform and run in the cloud, which is Apify's primary endeavor.
More InformationRelated ArticlesHeadless Chrome and the Puppeteer Library for Scraping and Testing the Web
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Tuesday, 18 October 2022 ) |