| Inside C# 4 Data Structs |
| Written by Mike James | |||||||
| Tuesday, 07 September 2010 | |||||||
Page 1 of 6 C# data structures are aggregates of any other data type you care to think of. Usually you can just ignore the details of using them but occasionally you need to get deep inside and control what happens. We look at how to control they layout of structs and how to pass them to unmanaged code. 
Structs are a fundamental data type in C# and most other modern programming languages. In C# structs are value type equivalents of classes which are reference types. In general structs can have methods as well as properties and they can be used in the same way as a class with the exception of inheritance - structs cannot inherit from another struct or another class. For the rest of this article we are going to ignore the object oriented aspects of the struct and concentrate on it as a data type - i.e. we are going to focus on the struct as a data structure. Data structures are inherently simple but you might be surprised at how fast things can become more complicated. The problems mostly arise when you have to work with structures created in other languages, either saved on disk or when calling functions in DLLs or COM. In this article I’m going to assume that you know what a struct is, how to define one and the basics of using one. I’m also going to assume that you have a rough idea of how to call an API function using p/Invoke and what marshaling is all about. If you are unsure of any of this the standard documentation will give you the basics. Many of the techniques described in this article can be extended to any data type. LayoutIn many situations you can simply declare and use a struct without worrying about how it is implemented – specifically how its fields are laid out in memory. If you have to provide structs for consumption by other programs, or use such “foreign” structs, then memory layout matters. What do you think the size of the following struct is? public struct struct1 A reasonable answer is 8 bytes, this being the sum of the field sizes. If you actually investigate the size of the struct using: int size = Marshal.SizeOf(test); you will discover (in most cases) that the struct takes 12 bytes. The reason is that most CPUs work best with data stored in sizes larger than a single byte and aligned on particular address boundaries. Pentium derived CPUs like their data in 16-byte chunks and like data to be aligned on address boundaries that are the same size as the data. So for example, a 4-byte integer should be aligned on a 4-byte address boundary i.e. the address should be of the form 4n-1. The exact details aren’t important. What is important is that the compiler will add “padding” bytes to align the data within a struct. You can control the padding explicitly, but notice that some processors throw an exception if you use data that isn’t aligned correctly. To control the layout of a struct you need to use InteropServices so add: using System.Runtime.InteropServices; The struct’s layout is controlled by a StructLayout attribute. For example: [StructLayout(LayoutKind.Sequential)] forces the compiler to assign the structure sequentially as listed in the definition, which is what it does by default. Other values of LayoutKind are Auto, which lets the compiler determine the layout , and Explicit, which lets the programmer specify the size of each field. Explicit is often used to create sequential memory layouts with no packing but in most cases it is simpler to use the Pack field. This tells the compiler exactly how to size and align the data that makes up the fields. For example, if you specify Pack=1 then the struct will be organised so that each field is on a byte boundary and can be read a byte at a time – i.e. no packing is necessary. If you change the definition of the struct to: [StructLayout(LayoutKind.Sequential, you will discover that it is now 8 bytes in size, which corresponds to the fields being laid out in memory sequentially with no packing bytes. This is what you need to work with most of the structures defined in the Windows API and C/C++. In most cases you don’t need to use other values of Pack. If you do set Pack=2 then you will find that the size of the struct is now 10 bytes because a byte is added to each of the byte fields to make the entire struct readable in 2-byte chunks. If you set Pack=4 then the size increases to 12 bytes to allow the entire struct to be read in blocks of 4 bytes. After this nothing changes because the pack size is ignored once it is equal or larger to the alignment used for the CPU –which is 8 bytes for the Intel architecture. The layout of the struct for different pack sizes can be seen in Figure 1.
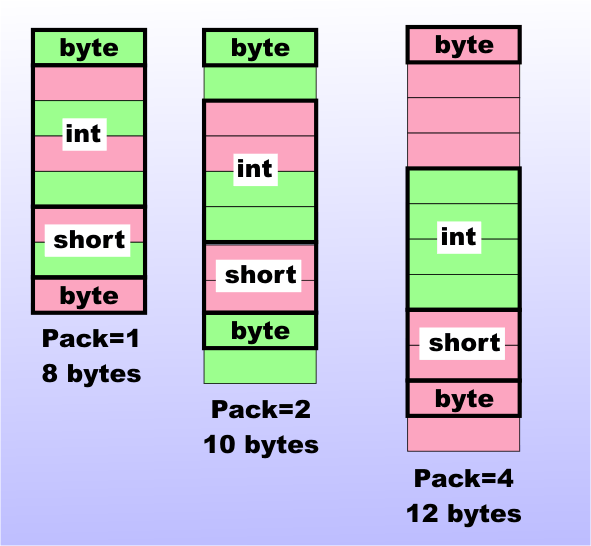
Figure 1: The effect of pack size on layout It is also worth mentioning that you can modify the way a struct is packed by simply reordering its fields. For example, by changing the field ordering to: public struct struct1 the struct doesn’t need packing and occupies just 8 bytes without the need for any intervention.
<ASIN:1449380344> <ASIN:1430225378> <ASIN:1933988924> <ASIN:3540921443> |
|||||||
| Last Updated ( Tuesday, 28 September 2010 ) |