| The First Things I Look At On A SQL Server – Part 2 |
| Written by Ian Stirk |
| Monday, 05 August 2013 |
|
In the first part of this series I looked largely at server-level information, in this article I will concentrate mostly on the database-level information.
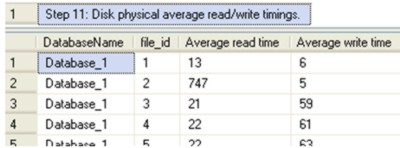
Following on from The First Things I Look At On A SQL Server – Part 1, this article resumes where we left off with Step 11 and continues in the same manner - rather than describe the code in depth, I’ll describe its purpose and meaning. The scripts relating to this article can be downloaded from the CodeBin and you can see the entire code in a separate window by clicking - Display Code. Where possible the script contains comments on what to look out for. In this article, we’ll look at disk speeds, reads per write, space usage, the state of statistics, missing indexes, missing primary keys, and queries taking the longest time to run. Step 11: Disk physical average read/write timings. This step shows the average read/write times, of the physical disks. Getting the data from the disks into memory can be expensive. The difference in performance can be seen by the fact disk access is measured in milliseconds whereas memory access is measured in nanoseconds. Values over 20 milliseconds are considered ‘bad’ and should be investigated. The DMV sys.dm_io_virtual_file_stats is used to calculate the average read/write times.
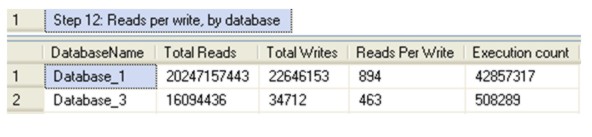
Step 12: Reads per write, by database Databases are typically divided into either transactional or reporting based. The number of reads per write will help differentiable the type of database, transactional databases have relatively fewer reads per write than reporting databases. You’ll notice even transactional databases often have many reads for each write. The type of database may influence your indexing strategy, storage costs and volumes, and identifying databases that may need a separate server etc.
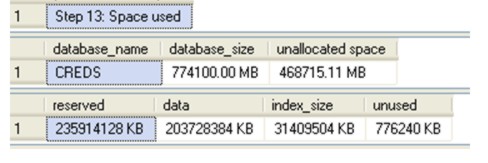
Step 13: Space used The system stored procedure sp_spaceused is used to determine how much space the database has been allocated, and how much is used/unused. Additionally the amount of space used by data and indexes are given separately. This can be useful in capacity management (you will need to record values periodically), and the need/impact of maintenance.
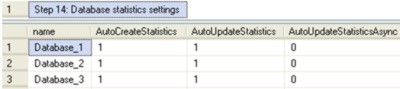
Step 14: Database statistics settings Database statistics can have a huge impact on performance. There are server-level settings of database statistics, taken from the system view sys.databases , these determine globally if statistics can be created or updated automatically. The default values should be used, unless you have a valid tested reason for changing them.
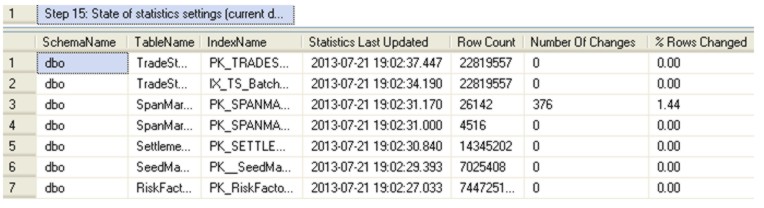
Step 15: State of statistics settings (current database) This step shows the current state of the statistics for the indexes in the current database. This includes when the statistics were last updated and the number of rows changed since that time. Statistics that are out of date can result in an index not being used or being used incorrectly (e.g. a scan instead of a seek). This step of the script is explained in detail in my article Improve SQL Performance – Know Your Statistics.
(click in screendump to enlarge)
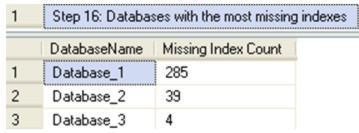
Step 16: Databases with the most missing indexes This step identifies which databases have the most missing indexes. A database that has many missing indexes can be indicative of other problems, and highlights the database may need further investigation.
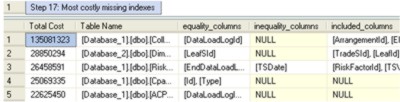
Step 17: Most costly missing indexes Indexes are crucial for query performance. This step identifies the most costly missing indexes, and implementing some of these indexes may significantly improve the performance of your queries. This step of the script is explained in detail in my article Improve SQL performance – find your missing indexes.
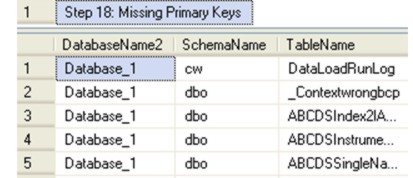
(click in screendump to enlarge) Step 18: Missing Primary Keys A primary key uniquely identifies a row in a table. Where possible, each table should have a primary key, unless you have a good reason not to create one (e.g. because the query uses all data in the heap). Also note a missing primary key means there is no related foreign key in any child tables – which is important for both referential integrity and performance (via indexing).
Step 19: Heaps with Non-clustered Indexes My internal tests have shown if you have heap with a non-clustered index, it is typically slower to load data than changing the heap to a clustered index based on the non-clustered columns. Where possible the heap should be converted to a table with a clustered index (and of course test the queries against the table performs faster).
(click in screendump to enlarge)
Step 20: Queries taking the longest total time to run This step identifies the individual SQL statements that take the longest time to run. This allows targeted improvements to be made. This step of the script is explained in detail in another article, Identifying your slowest SQL queries.
(click in screendump to enlarge) In this two part series we’ve looked at various server-level and database-level settings, all of which are useful when you’re investigating a SQL Server you’re unfamiliar with. I hope you will find these scripts of use. You can download the code for this program from the CodeBin (note you have to register first). Also in this series: Ian Stirk is the author of SQL Server DMVS in Action (see side panel, and our review) and the following articles:
Comments
or email your comment to: comments@i-programmer.info
To be informed about new articles on I Programmer, subscribe to the RSS feed, follow us on Google+, Twitter, Linkedin or Facebook or sign up for our weekly newsletter.
<ASIN:1935182730> |
| Last Updated ( Tuesday, 06 August 2013 ) |