| RAID - Storage Made Smart |
| Written by Harry Fairhead | ||||||
| Friday, 22 November 2024 | ||||||
Page 2 of 2
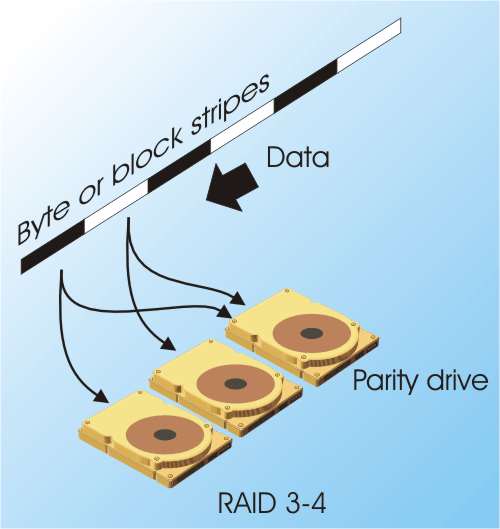
RAID 3 and 4RAID 3 and 4 are essentially variations and simplifications of the RAID 2 principle. They both use on-the-fly error detection codes which can also be used to reconstruct the data should a single drive fail completely. The most common configuration used is to add just one additional drive to the array to store a parity bit, which is 1 if the number of bits in the data is odd and a zero if it is even. RAID 3 uses byte striping and RAID 4 uses larger block striping and this is the only essential difference between the two.
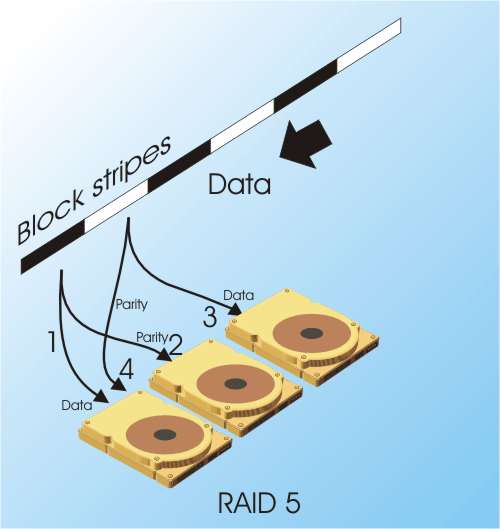
In theory RAID 4 is faster at random access than RAID 3 but a lot depends on the exact details of implementation. The biggest problem with RAID 3 and RAID 4 is their use of a single dedicated parity drive. The striping works in the usual way. The first block is written to the first drive and the second to the second and so on, but in addition parity data has to be written to the parity drive after each block. That is, the writing sequence goes: write block 1 to the first drive, write parity to parity drive, write block 2 to the second drive, write parity to the parity drive and so on. You can see that the parity drive is accessed every time a block of data is written or read and this make it a bottleneck on performance. The whole array can only work as fast as the parity drive and no overlapping of operation is possible. RAID 5RAID 5 is the most sophisticated of the RAID specifications in common use and you can think of it as a variation on RAID 3 and 4. It makes use of parity check data and block striping but now the parity data is distributed among all of the drives in use. That is, the parity data is treated as if it was just another block in the striped data and stored in turn on the next available disk drive. This simple change removes the bottleneck that a dedicated parity drive presents without impacting any other feature of performance. For this reason it is currently the most popular RAID configuration because it provides fault tolerance – one drive can fail without loss of data – without too much of a loss of storage or speed.
Beyond RAIDRAID 0 through 5 represent the original proposals for multi-disk arrays but since then others have been invented. The best known are 6, 10 and 50 but once you get the idea you can probably invent your own variations. RAID 6This adds a second parity drive to the RAID 5 setup. In this configuration two drives can fail without loss of data. In effect a RAID 6 system with a single failed drive reverts to being a RAID 5 system. RAID 10The numbering changes here because RAID 10 is a combination of RAID 1 and RAID 0. A RAID 0 system is used to provide larger storage capacity and throughput and a RAID 1 system is used to mirror the first system. This provides a fault tolerant configuration that is fast. RAID 50Again this is a mixture of two earlier RAID systems– RAID 0 and RAID 5. In this case a pair of RAID 5 systems is used to create a fault tolerant system and then RAID 0 is used to distribute the date across multiple drives so speeding up throughput. Practical RAIDAfter discovering the range of different ways arrays of disks can be used, a sensible question is which arrangements are easy to implement. There are two distinct ways to implement any RAID system – hardware and software. A hardware implementation of RAID simply attaches to a PC via the usual bus and the multiple disks that you connect to it look like a single drive. Everything is taken care of by the controller and you can simply take the RAID aspects for granted.You generally need a special driver and some management software that can see beyond the single disk drive that presents itself to the rest of the system. A slightly different approach to hardware implementation is the NAS or Network Attached Storage. This is essentially machine, usually running Linux or Windows, that implements a RAID system and makes the storage available via the network. It is essentially a RAID file server but it doesn’t need much configuration because it has been designed to do just one job. Software implementations of RAID are generally not as efficient but they are very flexible. Until quite recently any software RAID needed to make use of high performance SCSI drives, but now serial ATA drives are fast enough to do the job and are much cheaper. For example Windows Server supports RAID 0, which it refers to as a “striped volume”, RAID 1, which it refers to as a “mirrored volume”; and RAID 5. Linux also supports RAID 0,1,4,5 and 6 in software. What might be more surprising is that Windows desktop operating systems since XP Pro also support software RAID. What this means is that in nearly all modern desktop machines and servers adding RAID is simply a matter of adding another disk drive and configuring. Solid state drives SSDs have also confused the issue because they are so fast in general that the only reason for using RAID is to improve security. There is also the issue that SSD wear out. Each block in an SSD can only be written a limited number of times and there are algorithms to even out the wear. Not all RAID hardware supports wear leveling and this can cause drives to fail early. Some RAID configurations, RAID 5 and 6 for example, make this wear worse by constant writing of parity bits and so on. In this day and age of the cloud you might also be thinking that the days of in house RAID are well and truly numbered. The cloud is backed up but it isn't perfect and files are lost. Much better to have an in house RAID to mirror any cloud storage you might have - you can never have enough belts and bracers... To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
||||||
| Last Updated ( Monday, 25 November 2024 ) |