| QuickSort Exposed |
| Written by Mike James | |||||
| Thursday, 24 June 2021 | |||||
Page 3 of 4
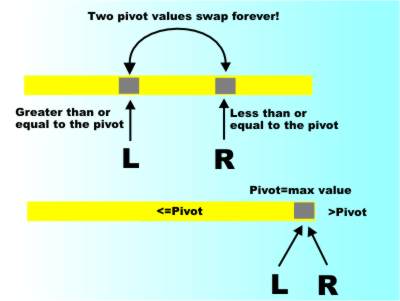
Moving The PivotThe reason is that for all values except the pivot the swap places them in the correct position never to be moved again during the scan – but the pivot isn’t always moved to the correct location in one go. For example, if the L pointer reaches the pivot it will be swapped with whatever value the R pointer has reached and will be swapped. This gives a value at the L pointer which is less than the pivot – which is what is required - but at the R pointer the new value isn’t greater than the pivot (it is the pivot!) and so may have to be moved again. The R pointer has to stay put on the pivot while the L pointer searches to see if it can find any values larger than the pivot to swap with it. So you can't just swap a pair of values and move the pointers on - you have to check that the two values are indeed smaller than or greater than the pivot before moving the corresponding pointer on. Pointers have to stick on the pivot. Notice that in this version of the scan we are actually partitioning the array into three parts – values less than the pivot, the pivot and values larger than the pivot.
The pointers meet at the pivot and divide the array into three parts
To summarize: In this version of QS it is vital that no pointer ever passes the pivot. This means that the pointers meet on the pivot and this is where the scan stops. If you automatically move the pointers on after every swap you might move one of the pointer over the pivot and leave behind forever in the wrong place.
This three-part division allows us to guarantee that the next stage always has a smaller array to sort. If the array was divided into two parts – values smaller than or equal to the pivot and values larger than the pivot this would not always be the case. Imagine picking the largest value in the array for the pivot! In this case the left-hand portion would be the whole array and the right hand portion would be null. You’d simply end up calling the QS algorithm on the entire array again. In the three-part division, selecting the maximum or minimum as the pivot, which can happen by chance, still reduces the array to be sorted by one because the pivot itself works its way to the top or bottom of the array and doesn’t play any further role in the sorting. That is, when the pointers meet and L=R the array to be sorted is always L-1 and R+1 because the pivot value is now stored at data(L)=data(R) and never has to be moved again.
Failing algorithms Subtle isn’t it! Great and it all works – well in most cases but there is one important case where it fails. The Case Of The Multiple PivotsThis is the classical solution to the scan and swap algorithm but it doesn’t always work. It only works if there is exactly one pivot value in the array. If there are two or more pivot values then the routine will simply hang in the infinite loop, swapping the equal pivot values backwards and forwards. I have seen this version of the algorithm presented without any comment concerning when it works or its validity. Be warned there are versions of the QS algorithm out there that not only assume that the pivot is in the list of values they also assume that the pivot is in the list exactly once. So what is the solution to the duplicate pivot problem? The Final ScanOne solution is to use a slightly different algorithm and not move the pivot on the left pointer at all. This stops the scans from hanging when there are duplicate pivot values but the whole procedure now hangs if the pivot is either the maximum or minimum in the array. The reason is simply that to cure the one problem we have gone back to splitting the array into two portions and when the pivot is the maximum or the minimum one of the portions is null and there is no change. There are a number of solutions to this problem and most of them are radical. However there is a simple modification to the classical approach that still splits the array into three parts and copes with multiple values of the pivot. All you have to do is test for the L and R pointers to be both pointing at the pivot and don’t repeatedly swap the values. Instead all you have to do is move the L pointer on to the next value. What sort of division does this weird modification to the pure algorithm produce? Well, the answer is that when the pointers meet all of the values to the left of the L pointer are less than or equal to the pivot, all of the values to the right of the L pointer are strictly greater than the pivot and the value pointed at by L is the pivot and it is in the right place. This means that we still have a three-part division and the array and none of the elements in any of the portions of the array have to be moved to another portion to sort it further. This means that the size of each portion to sort always shrinks even if the pivot is chosen to be the maximum or minimum value. The implementationAt last we have a practical, although some might say not elegant, algorithm. To make sure that the algorithm is 100% accurate let’s implement it using C# – although translation to other languages is easy. Start a new project and place a single button on the form. The sequence of events is to generate some data, sort it and print it:
We now have to write each of these routines and the routines that they use. The setdata routine is a simple shuffle of integer data. You should try other types of data including datasets with repeated pivots just to check that it all works.
The first for loop simply generates an array of data in order 1 to n. The second for loop then swaps each element with a randomly generated element. We need to write the swap routine, but as this is used within the quicksort itself this can wait till later. <ASIN:157586326X> <ASIN:1848000693> <ASIN:0470121688> <ASIN:0201558025> <ASIN:1565924533> |
|||||
| Last Updated ( Thursday, 24 June 2021 ) |