|
Page 1 of 3 Performing a computation sounds like a simple enough task and it is easy to suppose that everything is computable. In fact there are a range of different types of non-computability that we need to consider. In this article we try to answer the question of what is computable and what is not. This is probably the fundamental question of computer science.
This is an overview of what theoretical issues computer raise. Some of the topics are revisited in more depth in later chapters.
A Programmers Guide To Theory
First Draft
There is a more recent version of this:
Now available as a paperback and ebook from Amazon.

Contents
- What Is Computable?
- Finite State Machines
- What is a Turing Machine?
- Computational Complexity
- Non-computable numbers
- The Transfinite
- Axiom Of Choice
- Lambda Calculus
- Grammar and Torture
- Reverse Polish Notation - RPN
- Introduction to Boolean Logic
- Confronting The Unprovable - Gödel And All That
- The Programmer's Guide to Fractals
- The Programmer's Guide to Chaos*
- Prime Numbers And Primality Testing
- Cellular Automata - The How and Why
- Information Theory
- Coding Theory
- Kolmogorov Complexity
*To be revised
What can be computed?
We tend to think that computers can do anything.
If you can ask a question then a computer can help you answer it.
Perhaps at the moment it might just be beyond their reach but if you wait long enough the hardware will improve enough to get you an answer. It seems that the only real issue in answering a question by computation is how long can you wait for the answer.
However the truth isn’t quite as simple and the question “what can be computed?” doesn’t have a straightforward answer.
In some ways the answer to the question is almost more illuminating about the nature of the universe than a simple answer would be.
There is also the small matter that “what can be computed” depends on your definition of what represents a practical procedure. Some might be only interested in computations that can be completed in a reasonable time at reasonable cost. Others might be interested in what happens if you are prepared to allow any amount of hardware and time to be thrown at a problem.
What might surprise you is that even if you do allow any amount of computational power to be dedicated to a project there are still things you cannot compute!
This isn't about resources, it is more about logic.
However the nature of computation even for those things that we can work out is far from straightforward. There are computations that are inherently difficult to such an extent that even though we are logically allowed to know the result actually finding it is well beyond any reasonable resource allocation. What makes one problem difficult an another easy is an interesting study in its own right and this is where we start.
First let’s look at the more practical aspects of computation those that do relate to how long it takes to compute something.
Practical algorithms
When a programmer or theoretician thinks up a method of working something out, i.e. an algorithm, there is a variety of concerns. The first is that the algorithm should give an answer in a reasonable time.
This sounds like a simple requirement but an algorithm that works in a reasonable time for a small-scale problem can turn out to be unreasonable when the problem becomes bigger.
Computer scientists classify algorithms according to how they scale as the problem gets bigger. If N measures the size of the problem, the number of data points, dimensions, records and so on, ideally we would like an algorithm that takes the same time as N gets bigger.
Usually however the time taken to complete a task depends on N or N squared or some power of N. Such algorithms are said to take “polynomial time” and these are regarded as good algorithms. A polynomial time algorithm might well turn out to take too long in practice but you can always double the speed of the machine or invent something that makes it more reasonable.
The best algorithms that we can hope for is an algorithm that runs in constant time i.e. it doesn't matter how big the problem is the task takes the same time. For example, finding the first item in a list usually doesn't depend on how long the list is. If you can't find a constant time algorithm then an algorithm that takes a time proportional to the problem size is the next best - this is linear time. For example to find the last item in a list might require you to scan the entire list and this would take a time proportional to the length of the list N.
Next best is a quadratic time algorithm where it take N2 to get the job done. Imagine trying to find the brightest pixel in a photo of size N x N i.e. as there are N2 pixels it is going to take that long to find the brightest.
But wait surely if we just recalibrate and think of this as searching M=N2 pixels then we have a linear algorithm? True but we usually give the size of a photo a N not as the number of pixels and hence as we double the size of a photo the task increase four fold. There is always a certain arbitrariness about complexity but it usually doesn't matter.
The difficult algorithms are the ones that work in non-polynomial time. These include problems that don’t have a known solution at the moment and those that take exponential time, i.e. that take longer than any polynomial for large enough N. Non-polynomial time algorithms are the ones that blow up to the point where what you thought was just slow for 10 items suddenly takes more time than the universe has to run for 11 items.
Problems for which there is only an exponential time algorithm are called “difficult”. How do you know that a problem is difficult? There might be a better algorithm that has yet to be discovered.
Some problems are provably difficult because you can show that there can be no polynomial time algorithm that solves the problem. At the extreme there are the provably unsolvable problems for which it can be shown that no algorithmic solution can be found.
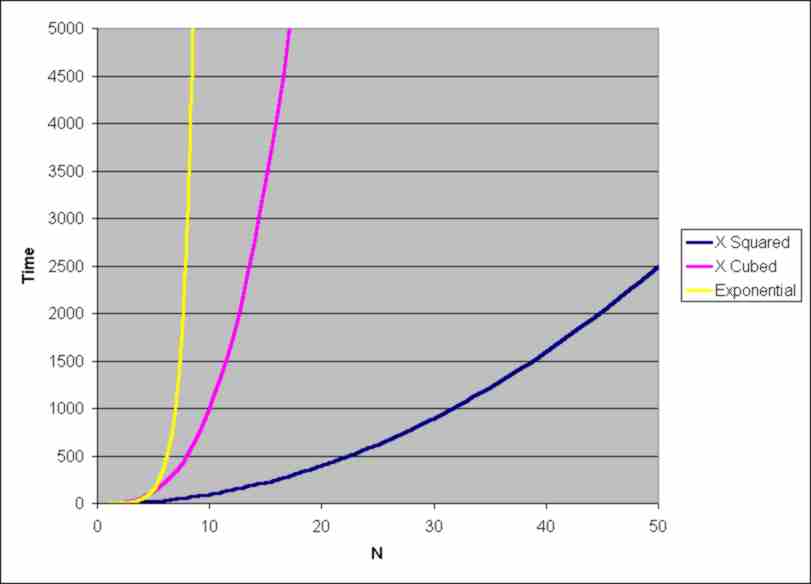
The time it takes to process N items is an important factor in how practical an algorithm is
Notice that what is important here is the "big number" behaviour of the time something takes. You don't have to worry about which algorithm is fastest for small problem sizes. If you have an algorithm that takes time roughly proportional to N and one that takes time roughly proportional to N2 then it might be that for a lot of small value of N the N2 algorithm is faster than the N algorithm. What you can be sure of however is that as N increases the N2 algorithm will slow down much quicker than the alternative - see the chart above to get the general idea.
This the reason why when it comes to working out how fast algorithms are in theory you don't have to seek small improvements and shaving off a few milliseconds here and there. Any practical optimizations you can work out only have an effect for a small range of small N. Eventually the very nature of the algorithms wins out and they show their real worth.
Also notice that there really are algorithms that work fine for small problem sizes but take completely unfeasible times for even modest size problems - like more than the age of the universe. However these things are just difficult to compute rather than uncomputable or theoretically unreachable.
<ASIN:0198604424>
<ASIN:0534949681>
<ASIN:1848001207>
|
