| What's In A DOS |
| Written by Harry Fairhead | ||||||
| Thursday, 11 October 2018 | ||||||
Page 2 of 2

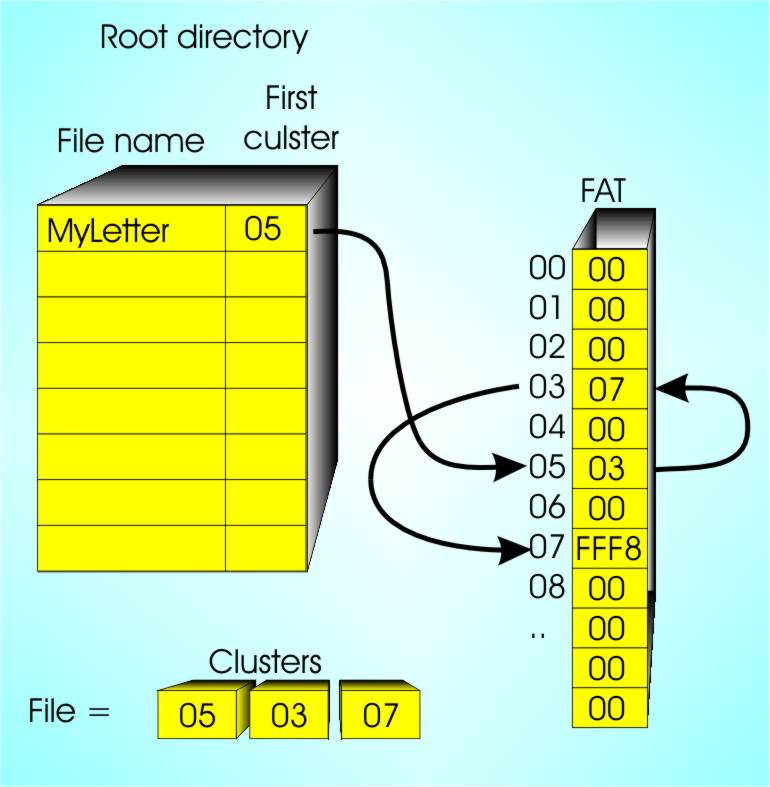
The FATWindows inherits MS-DOS’s filing system FAT – File Allocation Table. Although it has been superseded by the NTFS filing system in most cases it is still a supported option and often used for small and simple storage devices such as USB "drives". NTFS is more complex than FAT and hence doesn't make a good example. The FAT is a table of data written on the disk drive at a fixed location when it is formatted. In theory the table contains one entry for each block on the disk. When the FAT is first written to the disk every entry is zero and a zero is used to indicate that block is free for use. As well as the FAT the disk also contains a fixed area – the root directory - that is used to record filenames. Each root directory entry consists of a filename and the number of the first block in the file. As every file has at least one block, a directory entry that is all zeros is free for use. If the file consists of more than one block then the number of the second block is stored in the FAT. Where? The answer is that it is stored in the entry corresponding to the first block. That is, each entry in the FAT is either zero, indicating that the block is free for use, or it “points” to the next block in the “chain” and the start of the chain is stored in the root directory entry along with the file name. The final block in the chain is marked by the use of the special code FFF8 to FFFF. The code FFF7 is used to indicate that the block is damaged and should not be used. Reading a fileSo to read a file you first find its name, MyLetter say, in the root directory. You then know the number of the first block that it uses to store data – block 05 say. You can now read block 05 and process the data it contains. When you want to read the next block you go to entry 05 in the FAT and read the block number of the next block in the file 03 say. You can now read and process block 03. When you want to read the next block you look in the FAT in entry 03 to get the next block number. You carry on like this working your way along the file until the FAT entry is bigger than or equal to FFF8. At this point you know you have got to the end of the file and there isn’t another block.
Writing a fileWriting a file is just as easy. First you find a free root directory entry and store the file name in it. You then search the FAT for the first zero entry. When you have found a zero entry you know that the block with the same number as the table entry is free and so you store this number in the root directory. The program then generates data until it fills a block when it is written to the disk. Another block is then added to the file by first searching the FAT for a zero entry and then writing the number of the table entry in the previous FAT location. The process continues in this way until the final block is written and its entry in the FAT is set to FFF8 (or greater).
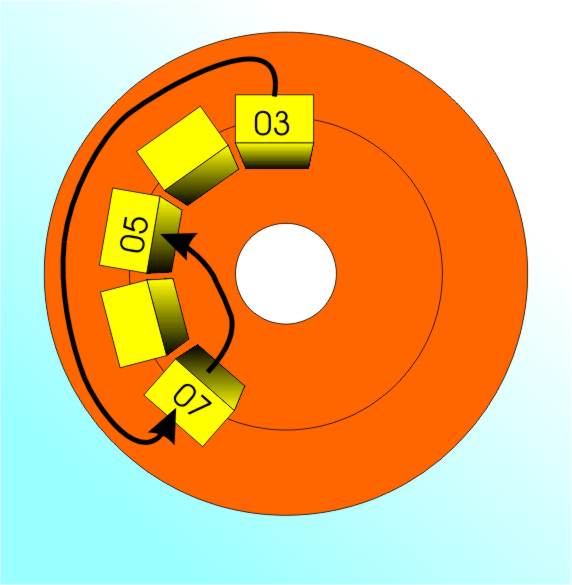
One advantage of using the FAT method is that files can be stored scattered all over a drive! EOFThe only subtle point is what the program is to do if it doesn’t use a complete final block? The answer is that most programs store an EOF or End Of File code to mark the end of useful data. In addition, the operating system stores a file length in the form of a byte count in the root directory which can be used to decide where the file ends. There are some other points of implementation but nothing too difficult or complex. For example, the block size used in the FAT is usually not a single cluster because this would make the FAT too large slowing things down and wasting disk space. Instead sectors which usually store 512 Bytes are grouped together to form clusters which are then treated as allocation blocks in the FAT. The number of clusters that a FAT can handle depends on the size of each entry in the FAT. The first FAT-based operating system used 12-bit entries and could handle 2^12 clusters, i.e. 4096. If each cluster is 4Kbytes, i.e. 8 standard sectors, this makes the largest disk that a FAT 12 system can manage, 32MBytes. As disks got bigger the FAT had to be extended to use 16-bit entries, i.e. 65536 clusters or 2GBytes using 64 sector clusters. Now we have FAT32 which uses 32-bit entries, i.e. 4,294,967,296 clusters or 2TeraBytes using 64 sector clusters. The advantage of knowing how the FAT system works is that many of the mysterious messages will now make better sense. For example, if a disk check on a FAT disk reports a lost cluster this corresponds to an allocation unit that has a non-zero FAT entry but isn’t part of any file – it’s lost, it’s come adrift – and the only sensible thing to do is convert it into a file. In fact errors of this sort in the FAT are so dangerous that the operating system keeps two copies of the FAT which it compares every time the machine is started. The only other important idea that we haven’t dealt with is the way the root directory is expanded to allow additional directories. Put simply the root directory can contain entries which point to files that are themselves treated as directories - i.e. sub directories. This is the reason that most filing systems are hierarchical and have a tree structure. Filing system such as NTFS and the Linux ext2 work in roughly same way - they all implement some method of keeping track of which blocks are used and belong to which files. Easy to say, but very difficult to do in an efficient and reliable way. To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.
Comments
or email your comment to: comments@i-programmer.info
<ASIN:1565922492> <ASIN:1292061421>
|
||||||
| Last Updated ( Thursday, 11 October 2018 ) |