| Geoffrey Hinton Says AI Needs To Start Over |
| Written by Mike James | |||
| Monday, 18 September 2017 | |||
|
Geoffrey Hinton is widely recognized as the father of the current AI boom. Decades ago he hung on to the idea that back propagation and neural networks were the way to go when everyone else had given up. Now, in an off-the-cuff interview, he reveals that back prop might not be enough and that AI should start over.
In an interview with Axios Hinton is credited with saying that he is "deeply suspicious" of back-propagation" and "My view is throw it all away and start again," The worry is that neural networks don't seem to learn like we do: "I don't think it's how the brain works. We clearly don't need all the labeled data." This might seem surprising from a pioneer in neural network techniques, but there is undoubtedly some truth in this reservation.
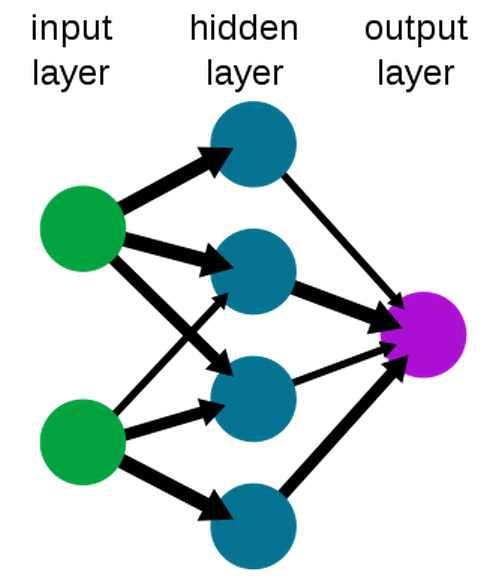
First it seems wrong to focus on unsupervised learning as being a problem.The idea that the brain somehow just sorts the world into order without the need for a teacher is only partly true. A common, and very successful, method of training neural networks is to provide large sets of labeled data and train the network to reproduce the labels. When presented with lots of pictures of categories of animals, say, the neural network is adjusted using back propagation to slowly get the classification right. That a neural network can learn a classification isn't surprising - given enough degrees of freedom and a good optimization algorithm, which back prop seems to be, then you can fit the data. What is really remarkable is that neural networks trained using back prop can generalize. They can correctly recognize images that they have never seen. They also seem to form plausible hierarchies of features which serve to make recognition possible. In short, a carefully trained neural network does seem to extract the structure of the data set.
Is this how the brain works? There is a good case for saying "who cares!". If you view AI as an engineering project, then we aren't really trying to build a brain that works in the same way as a brain. We are trying to build a device that does the same job by any means. In this sense a neural network that recognizes a cat is doing a good job, even if it doesn't do it in the same way as a human brain. However, it is true that humans don't seem to learn using labeled examples. One way that we learn is using rewards to guide our actions. This is reinforcement learning and it is also something that can be used with neural networks. Google's Deep Mind has had great success with creating networks that can play arcade games and even beat the world champion Go player. Alpha Go didn't learn the complex and subtle game of Go by being given labeled examples of moves. Instead it learned by simply winning or losing. It learned by engaging in play. This is unsupervised learning and is clearly not a problem for neural networks and yet this is one reason why it is suggested we need to reject back prop, even though back prop is central to the current success of deep reinforcement learning. However, not everything is good with back prop and our current learning methods. It is clear that we humans are reinforcement learning machines at some level and yet there lots of examples of us learning to do things that don't seem to involve reinforcement learning. Solve a maths problem and you are applying rules rather than reinforcement learning. AI researchers have long pursued symbolic reasoning systems as ways of mimicking this sort of human intelligence. It may not be as fashionable as deep learning at the moment, but it is still a valid approach to the problem of implementing many advanced systems and neural networks don't seem well disposed to symbolic reasoning. The whole problem comes down to neural networks being slow to learn. Back prop used with labeled data or reinforcement just doesn't seem to learn as fast as we do. A deep neural network doesn't have that "aha!" moment when you see the solution to a problem. Instead is moves like a glacier down a slope to an ever better solution. There is also the small matter that back prop doesn't seem biologically plausible. That is, our neural networks just don't do complex parameter updates using precise math. This isn't too much of a problem, however, because we have lots of suggestions that back prop doesn't have to be implemented accurately. Neural networks with low-precision arithmetic seem to work, and even the exact nature of the feedback correction doesn't seem to be vital - in principle. Yes, getting network training right matters when it comes to upping the performance of a recognition program from 99% to 99.1% but even if you get it slightly wrong the system still learns. This is the AI analog of the idea of universal computation, which suggests that Turing completeness is surprisingly easy to achieve and most even slightly complex systems have it. The AI equivalent is that, if you have something with enough degrees of freedom that can be optimized and apply that optimization the system for long enough, it will learn. In this sense back prop is probably just our over-engineered approach to providing corrective feedback to a system. It is a good idea to make use of it because, without it, our computational systems are too limited to provide the results in a reasonable time. The same is true of artificial evolution applied to neural networks - it works but far too slowly. It seems more likely that what we have in a neural network is not the system but the component. The neural network isn't the human brain any more than a transistor is a computer. They are both the components that can be used to build more complex and structured systems. What that structure is, and exactly what components are needed, is most likely the real challenge. It doesn't matter from a theoretical point of view if you build a computer from vacuum tubes or transistors. In the same way, it doesn't matter if our learning components use back propagation or something else. They are still components on the way to a full system.
More InformationArtificial intelligence pioneer says we need to start over Related ArticlesWhy AlphaGo Changes Everything Evolution Is Better Than Backprop? Artificial Intelligence - strong and weak Google's DeepMind Learns To Play Arcade Games //No Comment - Quantized Neural Networks To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Sunday, 13 October 2024 ) |