| Adversarial Attacks On Voice Input |
| Written by Mike James | |||
| Wednesday, 31 January 2018 | |||
|
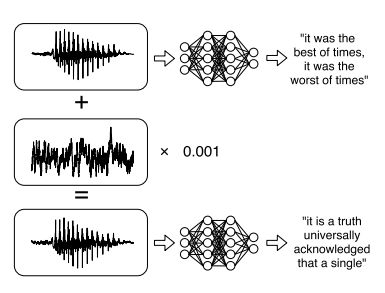
The Alexa, Google Voice, Siri or Cortana revolution is bringing voice control into every home. The AI revolution has started without us even noticing and it is far from secure. It seems to be fairly easy to issue commands that are recognized by the device, but sound completely innocent to a human. There is a flaw in every neural network and we have been aware of it for some time now. At the moment no certain fix is known, although there are a lot of possiblities. The real fix is probably to discover why neural networks behave in the way that they do and modify them so that they behave more like natural neural networks. What is this flaw? The simple answer is that you can train a network to recognize objects with a high degree of accuracy. You can then take the network's parameters and compute an adversarial image from any correctly classified image. The adversarial image will be modified ever so slightly, so slightly that a human cannot see the difference, but the neural network will now misclassify the image. Most of the time when a neural network misclassifies an image a human can sympathise and understand the mistake - "yes that dog does look a lot like a cat" - but an adversarial image reveals how different we are. You cannot believe that a neural network is in any way intelligent when it is claiming that an image of a cat is a banana or a car. The misclassifications seem to be silly. The problem, however, goes beyond silly with various research teams inventing examples where adversarial modifications can be made to real world object to mislead critical systems such as self driving cars. So far the field of adversarial inputs has focused on artificial vision and the convolutional neural networks that are used, but now we have examples of audio adversarial inputs. The basic idea is the same as for the visual case. You train a network to recognize command phrases such as "OK Google" or "Transfer My Bitcoin..." But now instead of turning one of the commands into something that isn't recognized although it sounds the same, you take some other sound and compute what small noise you have to add to it to make it recognized as one of the commands. The sounds that you start with could be a different phrase, a similar command, music or just noise. Does this work in practice? Nicholas Carlini and David Wagner of the University of California have used Mozilla's implementation of DeepSpeech and have managed to convert any given audio waveform to something that is 99% similar and sounds the same to a human, but is recognized as something completely different by DeepSpeech. You can hear some samples and what the network recognizes them as at Audio Adversarial Examples.
It works, but they used modified input files applied directly to the neural network. This is impressive, but the really worrying case is if it can be made to work over the air, i.e. by playing the audio to the microphone on a device like an Echo dot. This would make it possible to embed the adversarial example into a radio broadcast or advertisement, say, and make lots of devices do something their owners might not want. A team of researchers from a number of Chinese and US Universities and the IBM Research Center have followed a similar procedure, but using music and the open source voice recognition system Kaldi. In this case they have invented "CommanderSong" which is a modified version of a song, or music in general, perturbed enough to make Kaldi recognize a command, but not enough for a human listener to notice or even to guess what the command is. They tried applying the modified Wav files directly to the recognizer and achieved a 100% success rate in getting Kaldi to respond to the embedded command with a human having 0% success in identifying the command hidden in the song. Next they tried playing the Wav file using a microphone to pick up the sounds. With a really good speaker, they manged a 94% success rate and with other lesser speakers, including laptop audio, they managed from 89% down to 60%, but still with the human not having any idea what the hidden commands were. You can hear what the songs sound like at Commander song Demo. How worrying is all of this? From an academic point of view the real worry is that the adversarial problem needs investigating and a solution simply to find out how neural networks can be made more like real networks. From the security point of view what has been achieved isn't quite enough. Both adversarial attacks need to know the full parameters of the neural network, i.e. they are whitebox attacks. It is unlikely that, say, Amazon is going to publish the design and details of Alexa any time soon. However, there are blackbox attacks that use a great deal of data to probe an image network and eventually work out adversarial examples. At the moment this hasn't been done for audio - as far as we know. There is the matter that adversarial images are stranger than you might imagine. Not only can you engineer an adversarial image that fools a particular network, you can create "universal" adversarial images. These seem to be capable of causing a range of different networks to misclassify. At the moment it isn't clear if there are universal adversarial audio files that can be used to get a speech recognition device to respond to a command irrespective of its exact design. If such adversarial audio samples exist then it would be possible to design using a known network and then use the adversarial audio to attack all speech recognition devices that are listening. The idea that someone could buy a radio commercial and play a hidden command to every Alexa and Google Voice device listening may sound far fetched, but in the security world if there is a loop-hole it is only a matter of time before someone works out a way to make money or mischief using it. More InformationAudio Adversarial Examples: Targeted Attacks on Speech-to-Text by Nicholas Carlini & David Wagner CommanderSong: A Systematic Approach for Practical Adversarial Voice Recognition by Xuejing Yuan, Yuxuan Chen, Yue Zhao, Yunhui Long, Xiaokang Liu, Kai Chen, Shengzhi Zhang, Heqing Huang, Xiaofeng Wang and Carl A. Gunter Related ArticlesSelf Driving Cars Can Be Easily Made To Not See Pedestrians Detecting When A Neural Network Is Being Fooled Neural Networks Have A Universal Flaw Detecting When A Neural Network Is Being Fooled The Flaw In Every Neural Network Just Got A Little Worse The Deep Flaw In All Neural Networks To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 31 January 2018 ) |