| Google's Neural Networks See Even Better |
| Written by Mike James |
| Wednesday, 10 September 2014 |
|
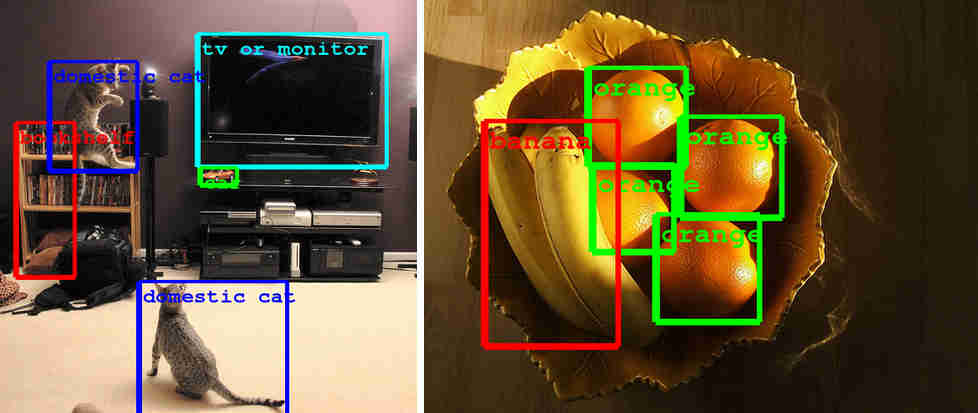
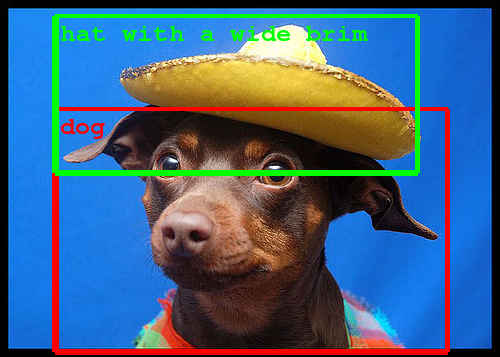
Recently Google's neural network team demoed a system that can recognize a lot of different things in photos. In this year's ILSRVC competition they have a neural network that can recognize multiple things in a single photo. The annual ImageNet large-scale visual recognition challenge, ILSRVC, is the a testing ground for all manner of computer vision techniques, but recently it has been dominated by convolutional neural networks which are trained to recognize objects simply by being shown lots of examples in photographs. This year's competition was different in that it allowed "black box" entries. If a team, or more likely a company, wanted to keep the workings of their algorithm a secret then they can keep the source code to themselves. , It would be interesting to speculate that some secretive company might astound us all with a black box that recognizes everything a human can without saying how it works. Less sensationally most entries opt to be open and share their source code and methodsm and most use some variation on a convolutional neural network. In 2012 there was a big jump in accuracy when a deep convolutional net designed by Alex Krizhevsky, Ilya Sutskever and Geoffrey E. Hinton proved for the first time that neural networks really did work if you had enough data and enough computing power. This is the neural network that Google has used in its photo search algorithm and, of course, the team they hired to implement it. This year's competition also brought a jump in performance. Google's GoogLeNet, named in honour of LeNet created by Yan LeCun, won the classification and detection challenge while doubling the quality over last year's results. This year the GoogLeNet scored 44% mean average precision compared to the best last year of 23%. GoogLeNet has made its code available to all. The classification task simply requires the software to label photos correctly and GoogLeNet scores a 6.65% error rate, which is close to the human error rate. It seems that we need a tougher test and this is what the detection task is all about.
The detection task requires different objects within the photo to be localized, i.e. classified and a bounding box to be drawn. This is moving in the direction of a neural network being able to perform scene analysis and description - a long-time goal of computer vision systems. The architecture of GoogLeNet hasn't been described in detail as yet but the team says: "At the core of the approach is a radically redesigned convolutional network architecture. Its seemingly complex structure (typical incarnations of which consist of over 100 layers with a maximum depth of over 20 parameter layers), is based on two insights: the Hebbian principle and scale invariance. As the consequence of a careful balancing act, the depth and width of the network are both increased significantly at the cost of a modest growth in evaluation time. The resultant architecture leads to over 10x reduction in the number of parameters compared to most state of the art vision networks. This reduces overfitting during training and allows our system to perform inference with low memory footprint." Even with a 10x reduction in parameters, the network still needed the help of the DistBelief infrastructure which can throw tens of thousands of CPU cores are the training problem using distributed algorithms. The Google Research blog entry describing the system has a very apt final paragraph: "These technological advances will enable even better image understanding on our side and the progress is directly transferable to Google products such as photo search, image search, YouTube, self-driving cars, and any place where it is useful to understand what is in an image as well as where things are." I'd add robots to the list and, as this is something Google is working on, it fits in with the Google product line very nicely.
More InformationBuilding a deeper understanding of images Large Scale Visual Recognition Challenge 2014 Related ArticlesThe Flaw Lurking In Every Deep Neural Net Google's Deep Learning AI Knows Where You Live And Can Crack CAPTCHA Google Uses AI to Find Where You Live Deep Learning Researchers To Work For Google Google Explains How AI Photo Search Works Google Has Another Machine Vision Breakthrough?
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
| Last Updated ( Sunday, 14 September 2014 ) |