| Google Open Sources Accurate Parser - Parsey McParseface |
| Written by Mike James |
| Friday, 13 May 2016 |
|
A lot of news items are making much of the naming of Google's English parser "Parsey McParseface", but there is some serious AI going on, as well as a sort of joke.
We tend to think these days that there is only one sensible approach to AI - end-to-end deep neural networks in which you put the raw data in one end and out comes the response you require. However, there are other more "structured" approaches. For example, you can tackle language understanding with an end-to-end approach just feed the words in and hope that meaning comes out. On the other hand, there is a long tradition of analyzing language using grammar. In this case you take a block of language and break it down into sentences and then the sentences into nouns and verbs and other parts of speech. Finding the grammatical structure of language is generally called parsing hence the name of Google's English parser - Parsey McParseface - and if you don't know where this strange construction comes from you have missed the recent controversy over the naming of a UK research ship. In good democratic style its name was put to a public vote and Boaty McBoatface was the winner. In a complete disregard for democracy the ship was named the Sir David Attenborough. I suppose you could say that Google has named the parser in honour of the Boaty McBoatface incident, but you could also just count it as another example of the poor naming of open source projects. Moving on to the actual code, which is what really matters. Parsey McParseface is claimed to be the most accurate linguistic model in the world. As you might guess there is a neural network involved, even if this is a traditional parsing approach to language understanding. Another thing you could guess is that SyntaxNet was built using TensorFlow, Google's open source framework for all sorts of parallel computations.
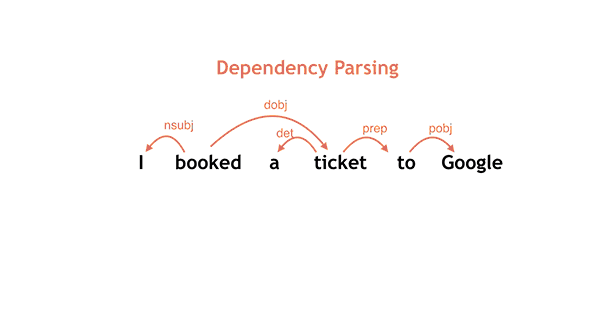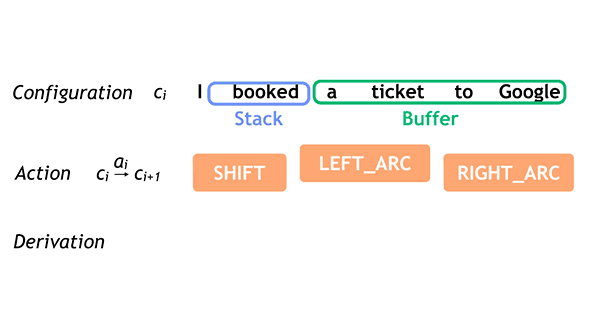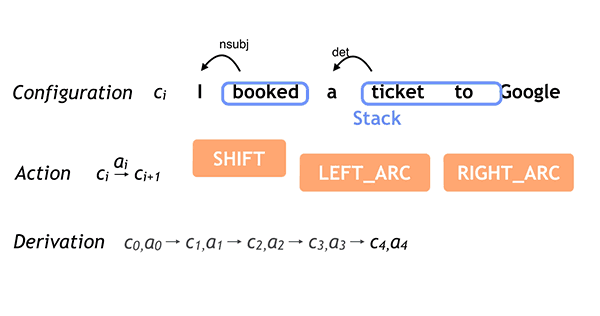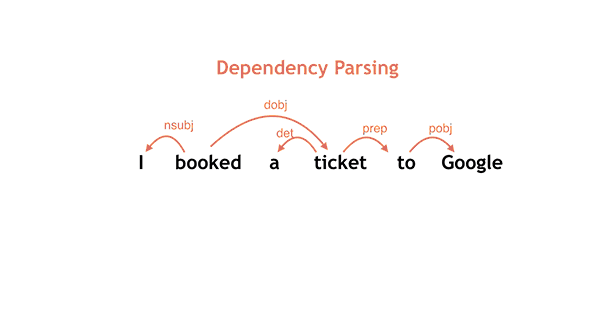
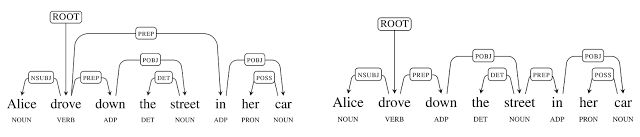
A parse in action
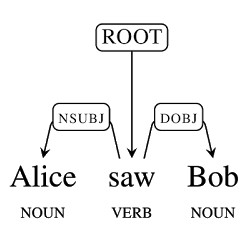
The neural network is trained by applying sentences with accurate parse sequences. When used to parse a sentence the words are presented one at a time and possible parses, as judged by the network, are kept. As words are added, the best parse changes and candidates are dropped. If this sounds easy you need to keep in mind what the blog says: "It is not uncommon for moderate length sentences - say 20 or 30 words in length - to have hundreds, thousands, or even tens of thousands of possible syntactic structures." The neural network is used to reduce this huge number of possibles to a smaller number of likely candidates.
Two correct parses but only one corresponds to the real world. If after staring at the diagram you don't see the incorrect interpretation think about the idea of there being a street in her car! Parsey McParseface is a trained example of SyntaxNet. You can use it to parse English texts and you can train SyntaxNet to produce your own specialized parser. Parsey, to use its first name, is good at dependencies between words, achieving 94% accuracy which is better than previous state of the art systems and approaching human performance on well formed text. On less well formed text it achieves 90% accuracy. This is claimed to be enough to be useful in real world applications. The errors that it makes will probably need a neural network working at a level other than syntax analysis, because they depend on real world knowledge to get right. What sorts of things can you use it for? While syntax analysis doesn't give you the meaning of a sentence it does help you towards the meaning. To know the subject, object and verb parts of the sentence can allow you to write a bot that responds correctly to commands. It can also be used to extract information from news stories and other text-based data. However you still have a lot of work to do to make any of these applications work convincingly. Syntax is only a guide to semantics.
More InformationAnnouncing SyntaxNet: The World’s Most Accurate Parser Goes Open Source Globally Normalized Transition-Based Neural Networks Related ArticlesNew Open Source Semantic Engine Handbook of Natural Language Processing
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info
|
| Last Updated ( Friday, 13 May 2016 ) |