| Zalando Flair NLP Library Updated |
| Written by Kay Ewbank | |||
| Tuesday, 08 January 2019 | |||
|
A new version of Flair, the simple Python Natural language processing (NLP) library has just been released by Zalando Research. Flair is built in Python on top of the PyTorch deep learning framework, and the updated version adds two new pre-trained frameworks that you can use. The developers say Flair gives a computer the ability to understand, tag and classify written texts: "Flair is useful when you want to understand the meanings of email messages, customer responses, website comments, or any other scenario where users submit text feedback that you want to automatically classify or otherwise process."
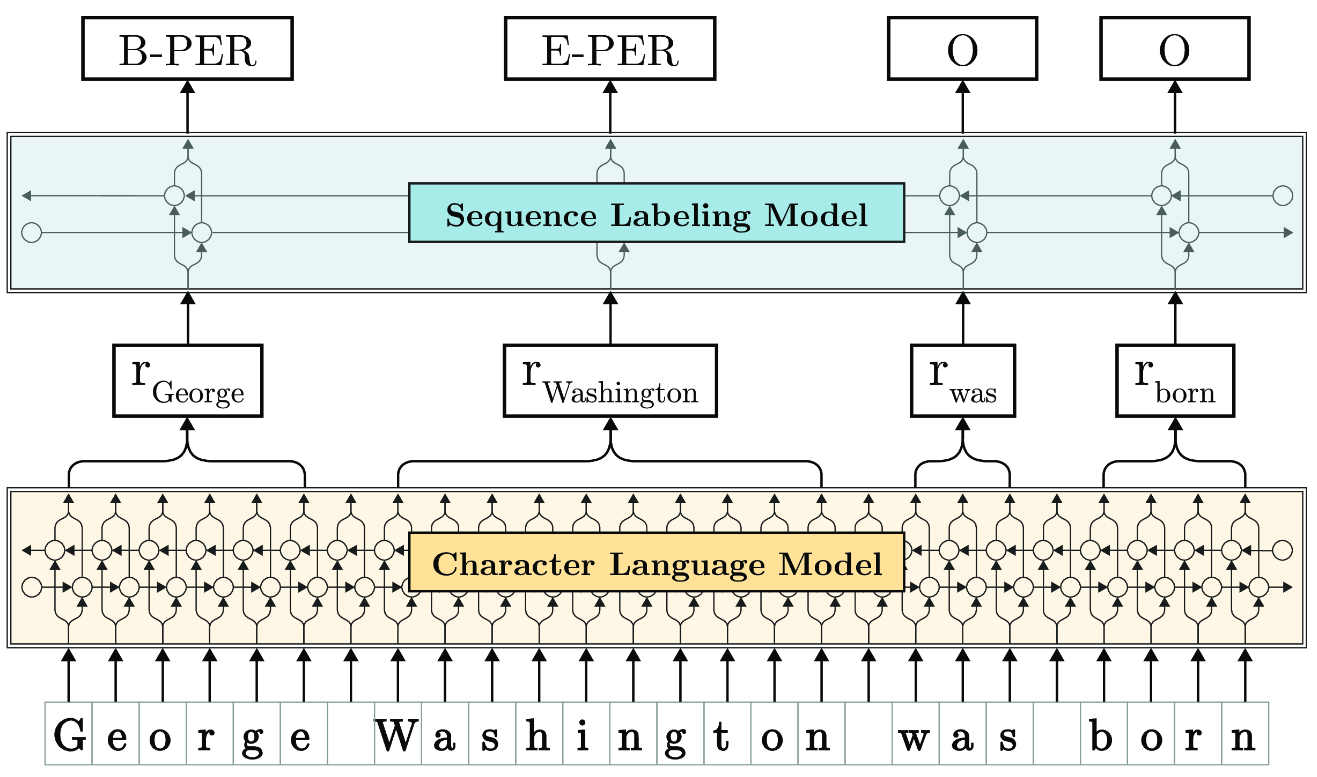
The developers say that Flair’s accuracy out-performs all of the previous best methods on a large range of NLP tasks. A recent paper titled "Contextual String Embeddings for Sequence Labelling" from Zalando Research discusses the approach taken by the software and why it outperforms the previous best methods. The diagram below shows the new approach:
Here, the sentence at the bottom is input as a character sequence into a bidirectional character language model (LM, yellow in Figure) that was pre-trained on extremely large unlabeled sets of text. From this LM, the software retrieves a contextual embedding for each word. It does this by extracting the first and last character cell states. This word embedding is then passed into a vanilla BiLSTM-CRF sequence labeler (blue in the Figure), achieving robust state-of-the-art results on downstream tasks (NER in this example). The new release adds two pre-trained models. These are a sentiment analysis model trained on the IMDB dataset, and an offensive language detection model that at the moment is limited to recognizing German offensive language. The sentiment analysis model can be used via a REST api and gives you a sentiment analysis service comparable to Google’s Cloud Natural Language API, but without the associated costs of using the Google API.
More InformationPaper On Contextual String Embeddings for Sequence Labelling Related ArticlesIntel Open Sources NLP Architect Google SLING: An Open Source Natural Language Parser Microsoft Expands Cognitive Services APIs
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Tuesday, 08 January 2019 ) |
 The library packages pre-trained models for NLP tasks, including named entity recognition (NER) to detect things like person or location names in text and part-of-speech (PoS) tagging to detect syntactic word types like verbs and nouns. It also supports sense disambiguation and classification. You can apply the pre-trained models provided to your text, or train your own sequence labeling or text classification models. Flair has simple interfaces that allow you to use and combine different word and document embeddings, including the framework's own Flair embeddings, along with BERT embeddings and ELMo embeddings
The library packages pre-trained models for NLP tasks, including named entity recognition (NER) to detect things like person or location names in text and part-of-speech (PoS) tagging to detect syntactic word types like verbs and nouns. It also supports sense disambiguation and classification. You can apply the pre-trained models provided to your text, or train your own sequence labeling or text classification models. Flair has simple interfaces that allow you to use and combine different word and document embeddings, including the framework's own Flair embeddings, along with BERT embeddings and ELMo embeddings