| Yahoo Opens Up Flickr Deep Learning |
| Written by Kay Ewbank | |||
| Friday, 04 March 2016 | |||
|
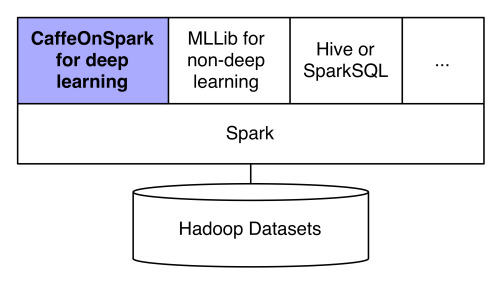
Yahoo is making CaffeOnSpark available for use by open-source developers. The deep learning software is used by Yahoo to gain intelligence from massive amounts of online data. CaffeOnSpark has been used by Yahoo internally for some time, including to improve the image recognition accuracy of Flickr. The Flickr teams used CaffeOnSpark to train Flickr using millions of photos from the Yahoo Webscope Flickr Creative Commons 100M dataset on Hadoop clusters. CaffeOnSpark is a Spark deep learning package that fills a gap in the Spark MLib, supporting dataframes to make it easier to interface with Spark-generated training dataset, and to extract predictions from the model as results or for data analysis using MLLib or SQL. MLlib is Spark’s machine learning (ML) library, consisting of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, and dimensionality reduction. The advantage of CaffeOnSpark over existing DL frameworks is that most of the other frameworks need a separated cluster for deep learning, along with multiple programs to create the machine learning pipeline.
Using separate clusters means large datasets have to be transferred between the clusters, and the pipelines add extra system complexity and latency. In contrast, the Yahoo project allows deep learning to be carried out in the same cluster along with existing data processing pipelines. The project is being released on Github: "to advance the fields of deep learning and artificial intelligence" according to a blog post by the development team. CaffeOnSpark can be tested on an AWS EC2 cloud or on your own Spark clusters. The release under open-source follows several other machine learning releases such as Google's TensorFlow, Microsoft's Computational Network Toolkit, and Facebook's Torch AI project.
More InformationHadoop blog Related ArticlesGoogle Open Sources Tensorflow Facebook Shares Deep Learning Tools To be informed about new articles on I Programmer, sign up for our weekly newsletter,subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 04 March 2016 ) |