| LinkedIn Open Sources Data Streaming Tool |
| Written by Kay Ewbank | |||
| Friday, 26 July 2019 | |||
|
LinkedIn has open-sourced its tool for streaming data between systems. Brooklin is described as a distributed service for streaming data in near real-time and at scale. The tool has been running in production at LinkedIn since 2016, and handles thousands of data streams and over 2 trillion messages per day. It exposes a set of abstractions that mean it can be extended to support consuming and producing data to and from new systems by writing new Brooklin consumers and producers.
Brooklin has been designed for use in multi-tenancy systems, and can simultaneously power hundreds of data pipelines across different systems. Creating new data pipelines or datastreams and modifying existing ones can be accomplished with just an HTTP call to a REST endpoint. Brooklin also exposes a diagnostics REST endpoint that you can use for on-demand querying of a data stream’s status. Source and destination systems don't have to be the same, and can be freely mixed and matched. Data streams are processed concurrently and independently meaning that errors in one stream are isolated from the rest.
The developers of Brooklin say that because it's a dedicated service for streaming data across various environments, all of the complexities can be managed within a single service, so application developers can focus on processing the data and not on data movement. The centralized extensible framework also means organizations can enforce policies. For example, Brooklin can be configured to enforce company-wide policies, such as requiring that any data flowing in must be in JSON format, or any data flowing out must be encrypted. Writing about the open source release, LinkedIn Engineering Manager Celia Kung said that Brooklin is used at LinkedIn as an alternative to Kafka MirrorMaker for mirroring Kafka data from one Kafka cluster to another: "Since Brooklin was designed as a generic bridge for streaming data, we were able to easily add support for moving enormous amounts of Kafka data." "One of the largest use cases for Brooklin as a streaming bridge at LinkedIn is to mirror Kafka data between clusters and across data centers. Kafka is used heavily at LinkedIn to store all types of data, such as logging, tracking, metrics, and much more. We use Brooklin to aggregate this data across our data centers to make it easy to access in a centralized place. We also use Brooklin to move large amounts of Kafka data between LinkedIn and Azure." The open source release is available on GitHub.
More InformationRelated ArticlesKafka Graphs Framework Extends Kafka Streams Apache Kafka Adds New Streams API LinkedIn Restricts Developer Access LinkedIn Developer Network Opens To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 26 July 2019 ) |
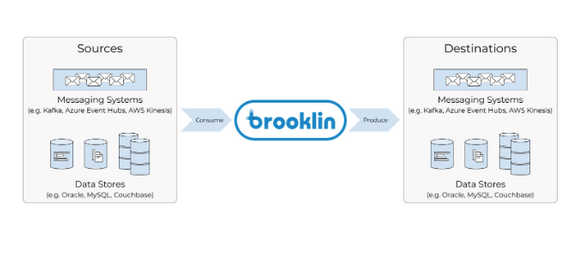
 LinkedIn uses Brooklin as the primary solution for streaming data across various stores including Espresso and Oracle, and messaging systems including Kafka, Azure Event Hubs, and AWS Kinesis.
LinkedIn uses Brooklin as the primary solution for streaming data across various stores including Espresso and Oracle, and messaging systems including Kafka, Azure Event Hubs, and AWS Kinesis.