| InfiniSQL - Try It For Size |
| Written by Kay Ewbank | |||
| Tuesday, 03 December 2013 | |||
|
A new SQL database designed to be infinitely scalable is being made available to developers for testing.
The modestly named InfiniSQL is designed to be scalable like NoSQL, but uses SQL for querying. The current benchmarks show that an InfiniSQL cluster can handle over 500,000 complex transactions per second with over 100,000 simultaneous connections, “all on twelve small servers”.
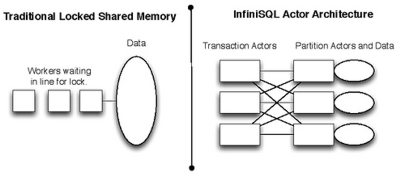
The creator of InfiniSQL, Mark Travis, was working at Visa processing transactions on Oracle and Sybase. In a guest post on the High Scalability blog, Travis explains that his background in big transaction processing environments, where a few seconds of downtime costs tens of thousands of customer dollars, taught him that “traditional enterprise database infrastructure is a terrible match for modern environments that need to be up 24x7, grow continuously, and rapidly respond to new business needs.” Convinced he could do better, Travis started work on his own database in his spare time two years ago. Some of the impressive performance is probably down to the fact that InfiniSQL currently stores and retrieves its data in memory rather than on disks, spanning multiple machine’s memory to achieve the scalability. This has the obvious downside that power loss means data loss. Travis is working on modules to write to disk as well as memory, but as he says in the blog post, InfiniSQL is “still in early stages of development” and more capabilities are necessary for it to be useful in a production environment. Travis says that InfiniSQL is ‘extraordinary’ because it performs transactions with records on multiple nodes better than any clustered/distributed RDBMS. That’s a big claim, but if the figures were to back up the claim, would make InfiniSQL an interesting proposition. He says InfiniSQL is intended for any company that has RDBMS workloads, but who has been forced to implement workarounds because their original RDBMS didn't grow with the business, with workarounds including sharding of SQL databases and migrating some workloads to various NoSQL point solutions. The other category of intended users for InfiniSQL is the one that Travis has real knowledge of – companies who have applications on monolithic platforms responsible for tens to hundreds of thousands of complex transactions per second, such as credit card associations. He points out that this kind of workload is difficult to move off of big box architectures, and that InfiniSQL is capable of performing this type of workload at intended volumes and beyond, but on x86_64 servers running Linux instead of big, super-expensive platforms. InfiniSQL implements a variation on the actor model of concurrent programming to overcome the twin problems of locking slowing down the database, and the need to write an accurate transaction log also slowing things down.
The actor model uncouples transaction processing logic from storage, and avoids locking memory regions. Processing logic is handled by one set of actors, and data storage is handled by another set. Messaging happens between actors regardless of the node that they reside upon. An actor that governs transactions doesn't know or care whether the data resides locally or remotely. In the other set of actors, an actor managing a particular data partition responds to messages regardless of origin. While the in-memory nature of InfiniSQL may be a concern, Travis points out that his plans for in-memory durability are borrowed from the world of high end storage, where changes are written to memory, and only later written to disk. Travis says: “They can get away with this because they have redundant battery backup systems and each write is distributed across multiple cache regions. No power loss or single point of failure can cause data loss in high end storage systems--and that's really what matters. The world's biggest transaction processing platforms rely upon this kind of storage array. InfiniSQL intends to implement the same model, except that redundancy and power management will protect database server nodes themselves. This has not been fully implemented yet, but when available, will mean that InfiniSQL will provide in memory performance with durability.” What Travis is promising sounds too good to be true, but each part of the description sounds reasonable. His background in high volume transaction processing makes me take him more seriously, and I suppose the only way to work out whether InfiniSQL can be as good as he says is to try it. InfiniSQL is free and open source, and Travis is looking for people willing to alpha test the software.
More InformationHow To Make an Infinitely Scalable Relational Database Management System Related ArticlesMemSQL - 80,000 queries per second
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info 
|
|||
| Last Updated ( Tuesday, 03 December 2013 ) |