| JetBrain's Developer Productivity AI Arena Is A Game Changer |
| Written by Nikos Vaggalis | |||
| Thursday, 20 November 2025 | |||
|
DPAI is an open platform for benchmarking AI coding Agents. Haven't we got enough benchmarks and evaluations already? To answer this question, yes we have; but for LLM performance, not coding agent performance. And by that we mean comparing for instance: Anthropic Claude Code CLI AI Agent and with benchmarks dedicated to software development tasks. Since software development is a multi-faceted paradigm, DPAI tests the agents on a diverse set of tasks:
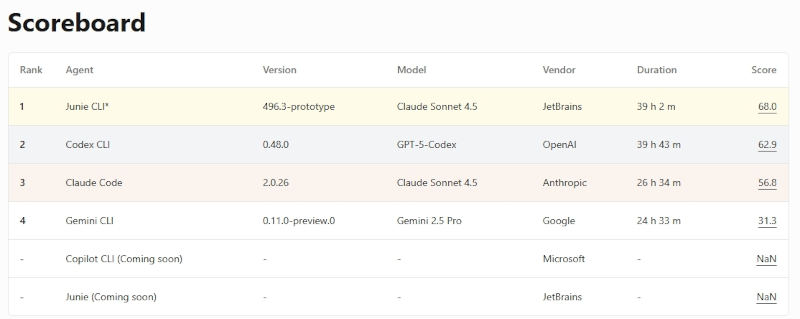
Each track is evaluated through two independent trials designed to measure both generalization (how well an AI coding agent performs without prior hints) and adaptation (how effectively it refines solutions once the expected tests are known). In the first trial, the Blind test, the coding agent receives only the task description and project context, without access to the hidden target tests. This setup simulates how real-world developers approach tasks with incomplete specifications. In the second trial, the Informed test, the environment is re-executed with a test patch pre-applied, giving the agent access to the target tests and allowing it to design its solution accordingly. The dataset consists of applications built using the Spring framework containing a set of 140+ tasks enterprise-grade requirements. Hence, a sample of a task that the agents were put under were : Task Description: * Utilize Spring's caching abstraction to cache the results of frequently repeated queries in the Petclinic REST API, reducing unnecessary database load and improving user response times. Identify key service methods to annotate with `@Cacheable` and configure an appropriate Caffeine cache manager. * Implement effective cache eviction and refresh policies to ensure data consistency and monitor cache performance. * Implement a stats endpoint that returns cache hit and miss metrics. * Test and benchmark the application to confirm improved efficiency, and provide clear documentation for maintainers and operators. Agent Junie of version 496.3 scored 63.3% on the Blind test. Acceptance Criteria: * Cache manager is configured with Caffeine * Key service methods are annotated with `@Cacheable` and integrated with the configured cache manager * Cache hits and misses are monitored * Admin endpoint `GET /api/cache/stats` returns hits and misses for each cache region. Regions: `pets`, `visits`, `vets`, `owners`, `petTypes`, `specialties` * Admin endpoint `DELETE /api/cache/clear` clears all caches * Admin endpoint `DELETE /api/cache/clear/{cacheName}` clears a specific cache region * Integration tests confirm correctness of cache statistics * Performance benchmarks demonstrate measurable improvements in response times and reduced database load * Documentation explains the caching strategy, policies and operational considerations where it managed to score a whooping 88.9%. The aggregated scoreboard re-affirmed that Junie scores better than the rest with 68% overall and Codex following with 62%. Of course the combination of the agent with the LLM model plays a big role. Thus the 68% percent belongs to Juni+Claude Sonnet 4.5, while the 62% to Codex+GPT-5-Codex. Personally, I'd like to a benchmark utilizing the IBM Granite 4.0 series too.
Saying that the platform is open, meaning that anyone can contribute domain-specific datasets, tracks, benchmarks and evaluation rules. And that's another strong point of the platform. As far as the end users, you the developer, goes, what's in for you? You can of course watch and evaluate how the agents perform in real-world battle tested situations in order to make up your mind on whom to use. Finally, Jetbrains intends to contribute the project to the Linux Foundation for gaining much wider community adoption and perhaps being adopted as a Standard. In any case this is a very welcome and useful contribution to the true spirit of open source.
More InformationRelated ArticlesIBM Launches Granite Version 4.0 and Granite-Docling
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |