|
Page 1 of 4 Python has a lot of data structures, but what if you want to create your own? Find out how it all works in this extract from Programmer's Python: Everything is Data.
Programmer's Python
Everything is Data
Is now available as a print book: Amazon
 Contents Contents
- Python – A Lightning Tour
- The Basic Data Type – Numbers
Extract: Bignum
- Truthy & Falsey
- Dates & Times
Extract Naive Dates
- Sequences, Lists & Tuples
Extract Sequences
- Strings
Extract Unicode Strings
- Regular Expressions
Extract Simple Regular Expressions
- The Dictionary
Extract The Dictionary
- Iterables, Sets & Generators
Extract Iterables
- Comprehensions
Extract Comprehensions
- Data Structures & Collections
Extract Stacks, Queues and Deques
Extract Named Tuples and Counters
- Bits & Bit Manipulation
Extract Bits and BigNum
Extract Bit Masks
- Bytes
Extract Bytes And Strings
Extract Byte Manipulation
- Binary Files
Extract Files and Paths
- Text Files
Extract Text Files & CSV
Extract JSON ***NEW!!!
- Creating Custom Data Classes
Extract A Custom Data Class
- Python and Native Code
Extract Native Code
Appendix I Python in Visual Studio Code
Appendix II C Programming Using Visual Studio Code
<ASIN:1871962765>
<ASIN:1871962749>
<ASIN:1871962595>
<ASIN:B0CK71TQ17>
<ASIN:187196265X>

Most of the time you can find a built-in class, or something from a predefined module, to satisfy your need for a data structure. If you need something custom then how much effort is worth expending on such a creation depends on many factors, but in most cases some level of integration with the general way Python handles data objects is desirable. In this chapter we look at ways of achieving this using magic methods and the Abstract Base Classes.
Indexing
How do you support indexing and slicing on a custom object? In many languages the answer would be that you can’t or that it was very difficult. In Python it is very easy and very natural. When you use [] with an object one of three methods is called:
-
__getitem__(key) when an indexed value is needed a=b[key]
-
__setitem__(key,value) when an indexed value is changed b[key]=a
-
__delitem(key)__ when an indexed element is to be deleted del b[key]- should really only be used for dictionary-like objects.
As an example we can add index access to the binary tree class described in Chapter 10. To do this we need to indicate how an index might map onto nodes of a binary tree. The simplest way of doing this is to use a breadth-first enumeration:
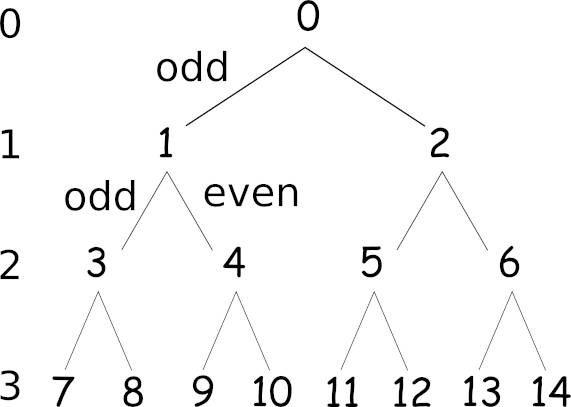
The problem of converting the index to the corresponding node is tricky, but given a function getNode(key) which returns the node at the specified key location then writing the index access functions is easy:
def __getitem__(self,key):
if isinstance(key,int):
return self.getNode(key)
raise TypeError("invalid index")
def __setitem__(self,key,value):
if isinstance(key,int):
self.getNode(key).value=value
else:
raise TypeError("invalid index")
You can see that the __setitem__ method simply sets the value attribute on the node. An alternative is to replace the entire node with a new node. With these and the getNode method defined you can write things like:
for i in range(0,16):
print(tree[i].value)
print(tree[16].value)
tree[10]=42
print(tree[10].value)
Notice that both __getitem__ and __setitem__ should raise an IndexError exception if the key is out of range, but in this case the error is delegated to getNode, see later.
Slicing
What if you want to extend the indexing to slicing? There is very little new in adding slicing to indexing – the same methods are used, the only difference is that a slice object is passed in place of an index. The real problem is how to interpret a slice for a non-linear data structure. In the case of the Tree example we can interpret tree[s:e] as being a request for the node objects with index tree[s] through to tree[e] returned not as a tree but as a list. This isn’t conceptually “pure” as a list isn’t really a slice of a tree, but it could be useful.
The only implementation problem is in handling all of the missing values that are possible in a slice. The slice object that the __getitem__ and __setitem__ methods use has three attributes start, stop and step. The problem is that not all slices define each one and when you don’t specify one of them they default to None. So, you can’t simply use:
range(slice.start,slice.stop,slice.step)
to generate index values in the specified range because range doesn’t accept None for any of its parameters.
A reasonable solution is to set up a maximum range for the object and then use the slice object to reduce it to the desired slice. That is with:
range(0,len(obj))[slice]
the [slice] notation is quite happy to accept None as any of the slice parameters.
Assuming that we have defined __len__ for the Tree class and it simply returns that total number of nodes in the Tree, we can write the __getitem__ method to accept a slice and return a list of nodes in the specified slice:
def __getitem__(self,key):
if isinstance(key,slice):
temp=[]
for i in range(0,len(self))[key]:
temp.append(self.getNode(i))
return temp
if isinstance(key,int):
return self.getNode(key)
raise TypeError("invalid index")
Notice that it still handles a simple index request. This probably isn’t the most efficient way to construct a slice from a tree, but it works. After defining this method you can write things like:
print(list(node.value for node in tree[3:9]))
As an alternative you could define the return slice as a list of node values rather than node objects.
To accept a slice the best interpretation is to allow a list of values to replace the values in the nodes in the specified slice. To do this we simply use the same technique, but this time we set the value of each node in the slice:
def __setitem__(self,key,value):
if isinstance(key,slice) and isinstance(value,list):
for i in range(0,len(self))[key]:
self.getNode(i).value=value.pop(0)
elif isinstance(key,int):
self.getNode(key).value=value
else:
raise TypeError("invalid index or value")
Notice that no check is made to ensure that value has enough elements to satisfy the number of elements in the slice. Once you have this modification you can write things like:
tree[3:6]=[1,2,3]
|