| Fractal Image Compression |
| Written by Mike James | |||||||||
| Friday, 08 April 2022 | |||||||||
Page 5 of 5
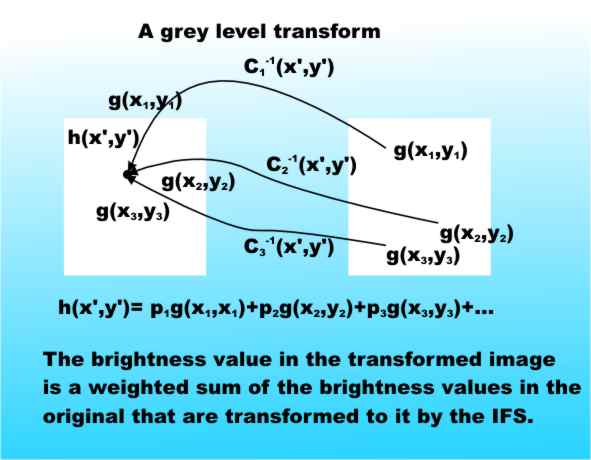
Grey level compressionThe contractive affine transformations and the compression methods that they give rise to have all been in terms of binary images. A grey level image can be dealt with in a number of different ways and all that really matters is that we use a suitable generalisation of a contractive affine mapping. The problem in trying to generalise the contractive affine transformations that we have been using is that they are put together, so to speak, using the idea of set union. This is possible because the black points in the image form a clearly defined set that can be modified by the affine transformations. In the case of a grey level image there is no set of points that we can concentrate on because every point in the image has a grey value. The solution to the problem is to consider the grey level image as a function - g(x,y) that associates a grey level with each point in the image and allow the IFS to transform this function replacing set union by addition. The way that this has to be done is a little confusing at first but it makes good sense. The brightness of the input image at x,y is given by g(x,y). The transformed image is h(x,y). To find the brightness of the transformed image at h(x',y') we have to add up the contributions of each point in the original image that has been transformed by the IFS to the point x',y'. If the IFS consists of transformations c1,c2 and so on these points are:
and so on. (Notice that we have to use the inverse transformation because we need to know the points in the original that have been transformed into the output image and the IFS maps points in the original to the output.) Adding these brightness values together would give you a brightness value that on average will be n times brighter than the original where n is the number of transformations. To keep the grey levels in the same range all we have to do is form a weighted sum of the brightness values. That is:
where the sum of all the p factors is one.
The transformation M(g(x,y)) generated in this way is a contractive affine transformation and so everything discussed earlier still works. That is, if you iterate M then the result converges to an attractor and the collage theorem still operates - if M(g(x,y)) is close to g(x,y) then the attractor of M is even closer. You can even use the same method of dividing up the image into range and domain blocks and looking for the best range block plus transformation to match each of the domain blocks. And of course once you have a method that works with grey levels you can use the same method for colour - just treat the colour image as three grey level images one for red, one for blue and one for green. The book Fractal Image Compression: Theory and Application (see side panel ) includes code for encoding and decoding images using fractals. Related ArticlesThe Programmer's Guide to Chaos Benoit Mandelbrot, the father of Fractal Geometry, dies The Programmer's Guide To The Transfinite
Comments
or email your comment to: comments@i-programmer.info To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
<ASIN:0387942114> <ASIN:1848310870> <ASIN:1584504234> |
|||||||||
| Last Updated ( Monday, 27 May 2024 ) |