| A Single Perturbation Can Fool Deep Learning |
| Written by Mike James |
| Saturday, 25 March 2017 |
|
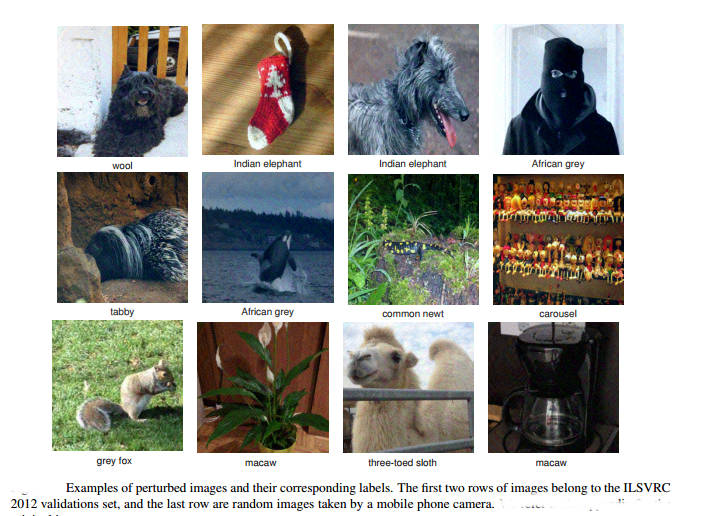
If you have been reading our reports on adversarial images, the headline should come as no surprise. What is a surprise is the way that AI researchers are regarding such images as security threats rather than a deep insight into the way neural nets work. It was a surprise when adversarial images were discovered. Put simply you can work out a small valued image, a perturbation, that when added to an existing correctly classified image will cause it to be misclassified even though a human can see no difference. It was hinted at the such perturbations disturbed the classification of a range of neural networks and perhaps even other machine learning approaches in the same way. Soon after, researchers at EPFL’s Signal Processing Laboratory discovered that not only was it possible to compute an adversarial image for a particular image and a particular network, you could find a single perturbation that was in a sense universal. What this means it that you can precompute a perturbation, add it to an image and you can be fairly certain that any AI on the receiving end will get it wrong no matter what their architecture. Notice that the perturbation is independent of the image.
We reported on universal adversarial images back in November 2016, Neural Networks Have A Universal Flaw, but now the paper has been accepted for presentation at the IEEE Conference on Computer Vision and Pattern Recognition taking place in Hawaii in July 2017 and there is a video explaining, or rather promoting, the research. However, rather than wonder at the mystery of it all and what it can tell us about neural networks, the angle is that of security: "Given a state-of-the-art deep neural network classifier, we show the existence of a universal (image-agnostic) and very small perturbation vector that causes natural images to be misclassified with high probability. We propose a systematic algorithm for computing universal perturbations, and show that state-of-the-art deep neural networks are highly vulnerable to such perturbations, albeit being quasi imperceptible to the human eye. We further empirically analyze these universal perturbations and show, in particular, that they generalize very well across neural networks. The surprising existence of universal perturbations reveals important geometric correlations among the high-dimensional decision boundary of classifiers. It further outlines potential security breaches with the existence of single directions in the input space that adversaries can possibly exploit to break a classifier on most natural images." You can also get a flavor of the research in the video:
This is possibly the most important unexplained aspect of neural networks and machine learning and it is being studied as a security or safety problem. What is some evil person misleads a machine intelligence? What if a self driving car is made to crash because an adversarial signal is injected into the video feed? None of these and many similar questions are as interesting as the fundamental question of what exactly is going on? It is clear that the adversarial perturbations are not "natural" images.They are regular and just don't occur in nature:
So the networks don't include them in their learning because they just don't see them. Is the human visual system subject to the same flaw? If not, why not?
More InformationWhen deep learning mistakes a coffee-maker for a cobra Universal adversarial perturbations by Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, Pascal Frossard Related ArticlesNeural Networks Have A Universal Flaw Detecting When A Neural Network Is Being Fooled The Flaw In Every Neural Network Just Got A Little Worse The Deep Flaw In All Neural Networks The Flaw Lurking In Every Deep Neural Net Neural Networks Describe What They See AI Security At Online Conference: An Interview With Ian Goodfellow Neural Turing Machines Learn Their Algorithms
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info
|
| Last Updated ( Saturday, 25 March 2017 ) |