| What Fools AI, Fools A Human |
| Written by Mike James |
| Wednesday, 03 January 2024 |
|
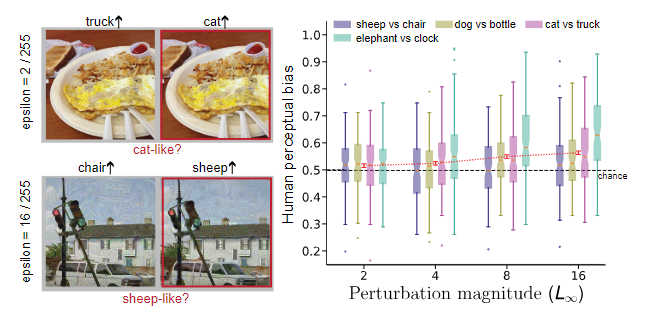
Before large language models became flavor of the year, convolutional networks were the hit. They solved the problem of computer vision, but they also introduced a new problem - adversarial images - which made them look silly and very, very, unhuman-like. Are neural networks implementing AI in the same way that our biological networks do? This is a deep and profound question. Convolutional neural networks have achieved a level of success in recognizing objects that is close to human abilities. Impressive but... then there are adversarial images. The idea is that you take an image that the network correctly classifies - a cat, say - and use an algorithm that moves the image away from the cat classification by making tiny changes to the pixel values. The values are so small that a human cannot consciously detect any change in the image and yet it is very possible for the neural network to be confused by it and classify a picture that is obviously a cat as a dog. This is too much for many observers who immediately draw the conclusion that AI is a silly trick that can't tell a cat from a dog when the evidence is right in front of it.
However we might have to think again. New work by Google's DeepMind suggests that humans, not just AI, are influenced by adversarial images. The researchers took adversarial images that the network got wrong and showed them to a human. Rather than asking if the cat looked like a dog - it didn't; they asked if the cat was "dog-like". By showing the human subjects unmodified images and adversarial images they could test to see if the humans were influenced. If there was no effect there should be no difference between the opinions of the modified and unmodified images. The distribution of "dog-like-ness" should be random. In fact, what was found was that the modified images were perceived to have moved in the direction that the neural network moved in. What is more, the response increased as the size of the modification increased. At no point was the change visible to the subjects, but as the size of the pixel modification increased so the cat looked more dog-like. The effect was also different for different adversarial images. As the report says: "From a participant’s perspective, it feels like they are being asked to distinguish between two virtually identical images. Yet the scientific literature is replete with evidence that people leverage weak perceptual signals in making choices, signals that are too weak for them to express confidence or awareness ). In our example, we may see a vase of flowers, but some activity in the brain informs us there’s a hint of cat about it."
So why is this important? One angle is that adversarial images allow adversarial attacks, which can make a computer vision system malfunction. Understanding the nature of adversarial images could give us a way to stop this. But for me, the most important aspect of the work is that it demonstrates that we are not so different. "Here, we find that adversarial perturbations that fool ANNs similarly bias human choice. We further show that the effect is more likely driven by higher-order statistics of natural images to which both humans and ANNs are sensitive, rather than by the detailed architecture of the ANN." I think it goes a little further than this. It demonstrates that despite the ludicrous sight of an AI declaring that a cat is a dog we share the same mechanisms and AI is heading in the right direction.
More InformationImages altered to trick machine vision can influence humans too Subtle adversarial image manipulations influence both human and machine perception Vijay Veerabadran, Josh Goldman, Shreya Shankar, Brian Cheung, Nicolas Papernot,Alexey Kurakin,Ian Goodfellow, Jonathon Shlens, Jascha Sohl-Dickstein, Michael C. Mozer & Gamaleldin F. Elsayed Related ArticlesThe Elephant In The Room - AI Vision Systems Are Over Sold? A Single Perturbation Can Fool Deep Learning Neural Networks Have A Universal Flaw Detecting When A Neural Network Is Being Fooled The Flaw In Every Neural Network Just Got A Little Worse The Deep Flaw In All Neural Networks The Flaw Lurking In Every Deep Neural Net Neural Networks Describe What They See AI Security At Online Conference: An Interview With Ian Goodfellow Neural Turing Machines Learn Their Algorithms To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
| Last Updated ( Wednesday, 03 January 2024 ) |