| Learning To Be A Computer |
| Written by Mike James | |||
| Wednesday, 29 October 2014 | |||
|
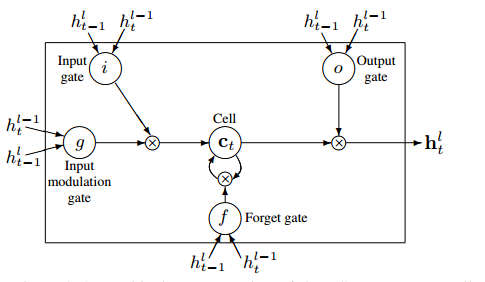
We have recently seen how much neural networks can learn, but the latest example is very strange. Google has succeeded in teaching a neural network to be a computer simply by showing it programs and what results they produce. Google's AI team has given us something else to think about. Most neural networks are of the feed forward type and these are characterised by having connections between layers that push the data forward to the output. That is there are no back connections and hence no feedback. Without feedback neural networks have no "memory" and always give the same output when presented with the same input - they are function learning machines. Networks that do have back connections are called Recurrent Neural Networks (RNN) and in the past these have been considered as more powerful but difficult to train. Some types of RNN have been invented that perform particular tasks and are easier to train. On example is the strangely named Long-Short Term Memory (LSTM) which acts as a gated memory element. However LSTMs aren't well understood in the roles that they can play in conjunction with other network components and learning rules.
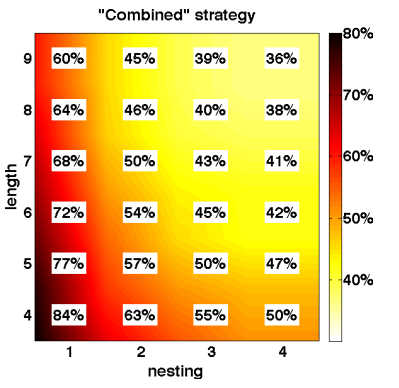
As an experiment to investigate LSTMs, Wojciech Zaremba and Ilya Sutskever decided to see how well an LSTM could learn to execute a Python program. Of course they had to restrict the type of program to give the LSTM a chance of working. The programs used can be evaluated in linear time and use addition, subtraction, multiplication, variable assignment, if statements and for loops - but not double for loops. Every program ends with a print that outputs a single number. The programs were characterized in difficulty by two numbers: their length, i.e. the number of characters used in the numeric values; and nesting the depth of a parse tree. Typical programs are
and
The neural network is given the programs one character at a time and produces one character at a time as output. The LSTM used has 400 units per layer. At first the networks were difficult to train and to try to make the task easier curriculum training was tried. This is based on the observation that biological learners do so faster if they are presented with simple examples and then the difficulty ramps up. The idea is that it is easier to master the complex cases when you know how the simple ones work. However, in the case of learning to execute programs, simple curriculum learning was actually worse then a random presentation. What worked best was a mixed strategy of graded exercises with some hard problems thrown in. The suggested reason for this is that when learning simple cases, the LSTM uses its entire memory capacity, even though this is not necessary. When the harder examples are presented the change needed to the structure to accommodate them is too great. The combined approach allows the network to learn simple cases while keeping it under stress by showing cases that are harder. What is surprising is that from being shown the training set the network could give the result of a program it had never seen. You present it with the text of a program and it outputs what the program would when run. Of course, the accuracty dropped as length and nesting increased - the fact that it was able to extract the structure from the character by character presentation sufficiently to predict the output of an unseen program is remarkable enough.
The researchers admit that they are unsure how the network manages the feat. You might think that this is just a matter of memory. The network could just store the inputs and outputs and when it sees the input again produce the same output. Simple memory doesn't account for the generalization that was observed. The network predicted outputs for programs it hadn't been shown. It is the ability to generalize which suggests that some part of the structure of the program as indicated by its text is being used to predict the output. What is particularly strange is that they report "interesting" errors such as being off by one. They speculate that the network might be learning approximate algorithms for things like addition. Instead of learning digit-wise addition with full carry, perhaps learning an addition table for just pairs of digits and using this to add multi-digit numbers without carry would give good, but not perfect, accuracy. I don't think that a neural network is going to form the basis of your next CPU, but looking at the ways in which algorithmic information can be extracted from text is a good way to explore how networks might come to "understand".
More Information
Related ArticlesSynaptic - Advanced Neural Nets In JavaScript Google's Neural Networks See Even Better The Flaw Lurking In Every Deep Neural Net Google's Deep Learning AI Knows Where You Live And Can Crack CAPTCHA Google Uses AI to Find Where You Live Google Explains How AI Photo Search Works Google Has Another Machine Vision Breakthrough?
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 31 October 2014 ) |