| Neural Networks Describe What They See |
| Written by Mike James | |||
| Wednesday, 19 November 2014 | |||
|
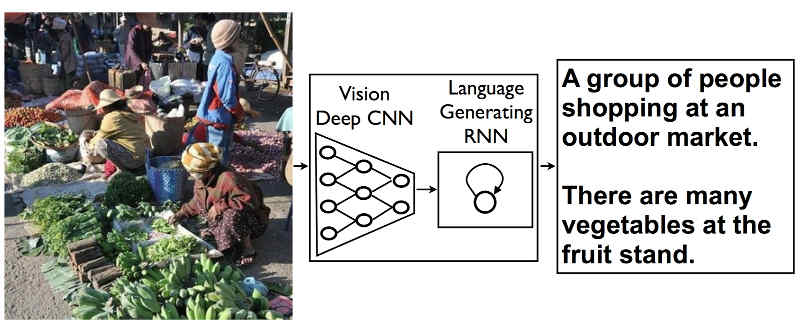
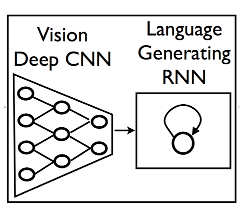
There has been an amazing growth in what neural networks can do and the next step is to put vision together with language to produce a network that can describe what it sees. At the moment, neural networks tend to be used to solve tasks with a single focus. For example, convolutional neural networks seem to be good at identifying objects in photographs. The more complicated recurrent neural networks seem to be good at language analysis. Sooner or later the state of the art will progress to the point where neural networks are assembled into systems that solve composite problems. This seems to be happening faster that you might expect as the news is that Google's AI team of Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan have bolted a convolutional neural network (CNN) onto the front of a recurrent neural network (RNN) to produce a combined network that can describe what it is looking at. In a blog post they describe how the idea came about: "This idea comes from recent advances in machine translation between languages, where a Recurrent Neural Network (RNN) transforms, say, a French sentence into a vector representation, and a second RNN uses that vector representation to generate a target sentence in German. Now, what if we replaced that first RNN and its input words with a deep Convolutional Neural Network (CNN) trained to classify objects in images?" You could say that the system was intended to translate pictures to words, rather than between languages. Normally the final layer of a CNN makes a decision about what the network is looking at based on the features detected by the lower layers. In this architecture the decision layer has been removed and the features are fed straight into the RNN which can produces phrases.
The whole system was trained by showing it images complete with suitable descriptive captions. The CNN learned the image features, the RNN learned the phrases that went with the features. The key factor in the success of any neural network application is how well the results generalize. That is, what does the network say when it is shown photos it hasn't been shown during training? In this case it seems to work well, On a test set a standard scoring system which gives a score of 69 to humans doing the task and 25 to previous AI attempts, the new system scores 59. For example, all of the following photos were not in the training set and the phrases generated seem appropriate:
If you still think that this is a trivial matching of phrases with input images, it is worth pointing out that about 50% of the time the system also generated phrases that were not in the initial training set - i.e. it created brand new descriptions. For example: the phrase:
was in the training set but the network also generated:
in response to appropriate photos. You can also learn a lot about how a neural network is working from its errors:
Even when it is completely wrong you can see how the mistake might have arisen. Clearly translation from pictures to words has potential for use in many application, but it still needs a much bigger training set before it could be let loose on the public. It is also obvious that the integration of vision with language is an important part of human intelligence. If you can convert an image to language you can use the language to reason symbolically about things.
More InformationShow and Tell: A Neural Image Caption Generator A picture is worth a thousand (coherent) words: building a natural description of images Related ArticlesNeural Turing Machines Learn Their Algorithms Google's Neural Networks See Even Better The Flaw Lurking In Every Deep Neural Net Google's Deep Learning AI Knows Where You Live And Can Crack CAPTCHA Google Uses AI to Find Where You Live Google Explains How AI Photo Search Works
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 19 November 2014 ) |