| Microsoft Open Sources AI Toolkit |
| Written by Mike James | |||
| Wednesday, 18 November 2015 | |||
|
After waiting for a big open source toolkit, two come along at the same time. Microsoft follows Google in providing the world with a way to do advanced distributed AI. Earlier this month Google open sourced TensorFlow, the tool that it uses internally for a wide range of parallel computations, including implementing neural networks and other AI learning methods.
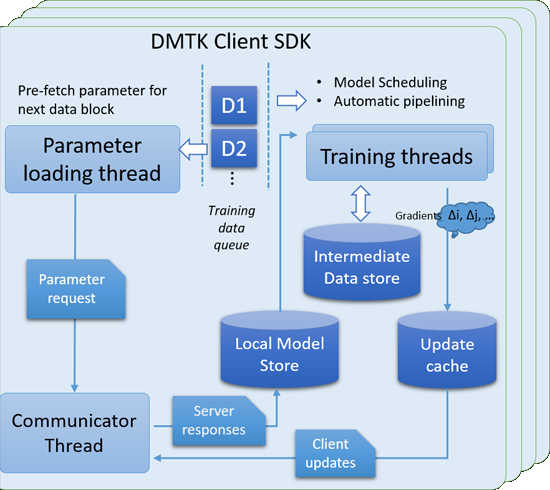
This toolkit includes three key components: • DMTK Framework: a flexible framework that supports unified interface for data parallelization, hybrid data structure for big model storage, model scheduling for big model training, and automatic pipelining for high training efficiency. • LightLDA, an extremely fast and scalable topic model algorithm, with a O(1) Gibbs sampler and an efficient distributed implementation. • Distributed (Multisense) Word Embedding, a distributed version of (multi-sense) word embedding algorithm.
The DMTK seems to be the core of the general purpose part of the toolkit - not all machine learning techniques need a Gibbs sampler nor take a word2vec approach. The DMTK is a client server system written in C++. This allows a single model to be computed across a number of servers. Microsoft claims that it handles a topic model with one million topics and a 20-million word vocabulary, or a word-embedding model with 1000 dimensions and a 20-million word vocabulary, on a web document collection with 200 billion tokens utilizing a cluster of just 24 machines. That workload would previously have required thousands of machines. Compared to the TensorFlow approach to AI, this doesn't seem to be as general purpose. TensorFlow is based on a flow graph approach to computation and hence can be used to implement any system that can be specified as a flow graph. The Microsoft framework is focused on topic models and word embedding. with: "...the potential to more quickly handle other complex tasks involving computer vision, speech recognition and textual understanding." It seems that Microsoft is hoping that other researchers will use the framework as a way to extend their own single machine models to a distributed computational environment. Machine learning researchers and practitioners can also build their own distributed machine learning algorithms on top of this framework with small modifications to their existing single-machine algorithms. "We believe that in order to push the frontier of distributed machine learning, we need the collective effort from the entire community, and need the organic combination of both machine learning innovations and system innovations. This belief strongly motivates us to open source the DMTK project." Overall, the quality of the documentation and examples aren't up to what Google has made available, but it you are an expert this might not matter.
Any success that the DMTK is going to have will come from how good it is at computing big models fast and this is something only time will tell. It does seem that it might be better than TensorFlow at making use of distributed computing, especially considering a version of TensorFlow that works with multiple servers has yet to be released. TensorFlow, on the other hand, is general enough and easy enough to use to get new blood into experimenting with AI.
More InformationDistributed Machine Learning Toolkit Microsoft open sources Distributed Machine Learning Toolkit for more efficient big data research Related ArticlesTensorFlow - Googles Open Source AI And Computation Engine RankBrain - AI Comes To Google Search The Flaw In Every Neural Network Just Got A Little Worse Inceptionism: How Neural Networks See Google's DeepMind Learns To Play Arcade Games Facebook Shares Deep Learning Tools To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Wednesday, 18 November 2015 ) |