| TensorFlow 0.8 Can Use Distributed Computing |
| Written by Mike James | |||
| Thursday, 14 April 2016 | |||
|
The only real problem with the previous release of Google's TensorFlow was that it would only work on one computer. Training neural networks is computationally intensive so the good news is that the latest release can make use of as much hardware as you can throw at it.
If you think that creating a neural network model is the big problem in AI, then you have never tried to train one. There is an intellectual challenge in understanding the architecture of a neural network but there is a practical challenge in finding out if it does anything useful. You not only need bucket loads of data, well oil tanker loads to be accurate you also need the computing power to deal with it. In general one machine, even with a good GPU is not enough. This was the main problem with the recently released TensorFlow program. It is a very nice tool to define all sorts of calculational models, but waiting while they computed was often just not practical. It has been announced that Google will not open source the version of TensorFlow that works on cloud facilities but a version that works on distributed hardware was promised with the first release.
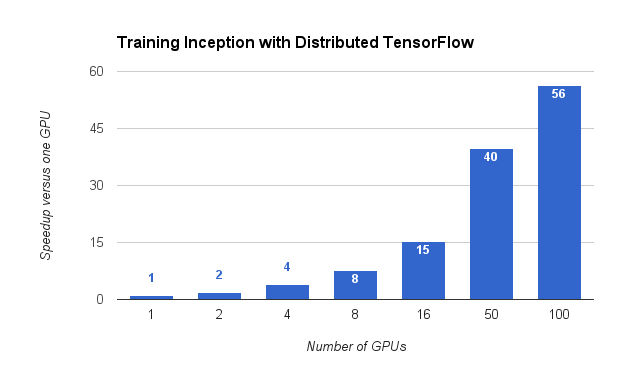
The Google research blog points out that- "Distributed TensorFlow is powered by the high-performance gRPClibrary, which supports training on hundreds of machines in parallel. It complements our recent announcement of Google Cloud Machine Learning, which enables you to train and serve your TensorFlow models using the power of the Google Cloud Platform." So, if you want to use your own hardware you can have the open source code, but it you want to use Google's hardware you have to have it as a service. In case you are in any doubt how important the distributed version is Google has also made available a distributed trainer for the well-known Inception architecture. You can see the effect on training time in the graph below: You can also see that as you throw more hardware at the problem the benefits diminish - but in this particular game it is still worth it. Long training times mean that you can't experiment effectively with new techniques and even tuning a network becomes difficult. It is worth noting that it takes about 2 weeks to train Inception using 8 GPUs. It only took 65 hours with 100 GPUS. However, it is also worth noting that TensorFlow has a reputation for not being the fastest Neural Network program available so this speedup is doubly worthwhile as it is flexible and easy to use. Of course there are some other new features in 0.8. In particular there are new libraries for distributed models. "To make TensorFlow easier to use, we have included Python libraries that make it easy to write a model that runs on a single process and scales to use multiple replicas for training. " TensorFlow looks like being and even bigger hit in the future. In the last year the GitHub repo has been forked over 4000 times, making it one of the most popular projects. More InformationAnnouncing TensorFlow 0.8 – now with distributed computing support! Related ArticlesGoogle Tensor Flow Course Available Free How Fast Can You Number Crunch In Python Google's Cloud Vision AI - Now We Can All Play TensorFlow - Googles Open Source AI And Computation Engine More Machine Learning From Udacity Nanodegree Plus Offers Guaranteed Jobs
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin.

Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Thursday, 14 April 2016 ) |