| JetBrains Finds Spreadsheets Still Favorites For Big Data |
| Written by Kay Ewbank |
| Wednesday, 21 July 2021 |
|
Given the fantastic tools available for big data analysis, the latest survey by JetBrains has found that the favorite statistical tool for analysis among respondents was.... the spreadsheet. Who'd have thought it! The latest JetBrains Developer Ecosystem Survey report has been released and as usual has findings that are both interesting and amusing. This is the fifth annual survey by JetBrains of the overall developer ecosystem, and the questions relating to big data threw up some surprises, along with a recognition of the importance of AWS and Apache in this sector.
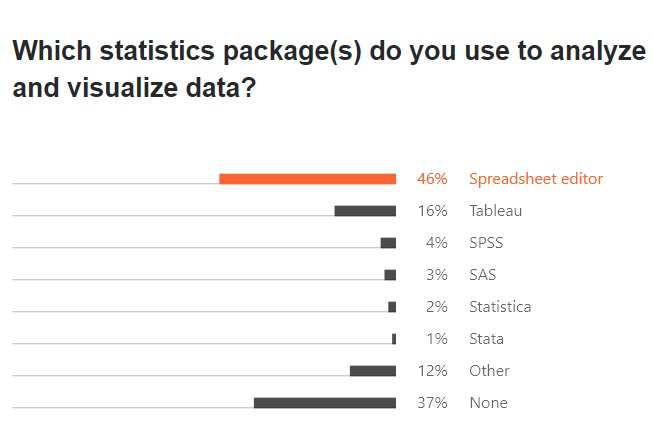
Spreadsheets came in as the tool of choice for 46% of developers working in big data, followed closely at 37% by None. Among the specific tools, Tableau was the leader at 16%, with SPSS still chugging along at 4%. The questions were shown to developers involved in Data Analysis, Data Engineering, Machine Learning, or to those whose job role was Data Analyst / Data Engineer / Data Scientist.
The survey did also return more reasonable sounding results. When asked what big data tools developers used, Jupyter was the most popular choice, used by 32% of big data developers. Other popular tools are Apache Spark (20%) and Apache Kafka (17%), along with Apache Hive, Flink and Pig. A fascinating set of answers showed that when asked about the big data analytics platform the developers used, most (68%) said they didn't use one. Heading the list of ones that are in use is Google Colab (19%), with Google AI Platform second at just 7%, and Databricks at 4%. The choice of where data is stored was also not what you might expect. For most developers, data is hosted on internal servers (36%) or locally (26%). AWS is used for data hosting by 21% of the respondents, with Google Cloud at 8% and Azure at 5%. When the survey analyzed the top ten combinations of big data tools in use by respondents, number one was Apache Spark and Apache Kafka, used by 10% of respondents. 9% use both Apache Spark and Apache Hadoop, or Jupyter and Spark. 7% used Hive and Spark, 7% Hadoop and Kafka. The other entries on the list combined Hadoop, Jupyter, Hive, Spark and Kafka in various combinations. In terms of languages used, the three most popular used along with Apache Kafka are Python, Java, and SQL. When considered alongside which data platform the developer works on, Python and Java are more commonly used with Google Cloud, JavaScript and PHP are more commonly used with AWS, and C# is more commonly used with Azure.
More InformationThe State of Developer Ecosystem 2020 Related ArticlesJetBrains Survey Reveals Professional Developers Spend Spare Time Programming JetBrains Survey 2019 - Do You Dream Code? Are You A Typical Developer? - JetBrains Survey 2018 Stack Overflow Survey 2020 - What Professional Developers Use
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |