| Open Source Time Series Database Released |
| Written by Kay Ewbank | |||
| Friday, 31 March 2017 | |||
|
A new, open-source time series database built with the Postgres engine has been released. TimeScaleDB is currently available in a single-node version, and is optimized for fast ingest and complex queries. The developers say that it offers advantages because unlike traditional RDBMS, TimescaleDB it scales-out horizontally across multiple servers; while unlike NoSQL databases, it natively supports all of SQL The database was created because its developers needed to deal with time scale data that was high in volume and complex in nature, with multiple measurements and labels associated with a single time. Storing such time-series data requires both scale and efficient complex queries. The developers say they were unwilling to make the trade-off between the horizontally scalability of NoSQL and the query power of relational databases: "We needed something that offered both, so we built it". The SQL support comes courtesy of the PostgreSQL engine, and includes features such as secondary indices, JOINs, and window functions. TimescaleDB acts and appears as though it is just a PostgreSQL database: You connect to the database as if it’s PostgreSQL, and you can administer the database as if it’s PostgreSQL. Any tools and libraries that connect with PostgreSQL will automatically work with TimescaleDB. The developers say TimescaleDB offers advantages over straight PostgreSQL because PostgreSQL does not scale well to the volume of data that most time-series applications produce, especially when running on a single server. They say that in particular, vanilla PostgreSQL has poor write performance for large tables, and this problem only becomes worse over time as data volume grows linearly in time. These problems emerge when table indexes can no longer fit in memory, as each insert will translate to many disk fetches to swap in portions of the indexes’ B-Trees. These problems with SQL databases in general led to the NoSQL movement, but the developers of TimescaleDB say that Time-series workloads are different in two key ways. Firstly, time-series data is largely immutable. New data continually arrives, typically corresponding to the latest time periods. In other words, writes primarily occur as new inserts, not as updates to existing rows. Secondly, workloads have a natural partitioning across both time and space. Writes typically are made to the latest time interval and across the “partitioning key” in the space dimension (e.g., data sources, devices, users, etc.). Queries typically ask questions about a specific time series or data source, or across many data sources
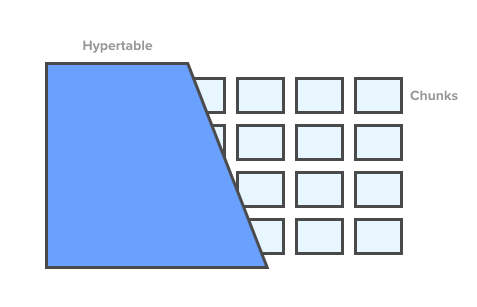
TimescaleDB makes use of these properties by automatically partitioning data into two-dimensional chunks across multiple nodes (or a single node), performing parallelized operations and optimized query planning across all chunks, and exposing a single table interface to this data (a “hypertable”). TimescaleDB provides the illusion of a single continuous database table across all time and space, even though this table is split into many chunks across servers. You run standard SQL queries against this hypertable, and the TimescaleDB distributed query planner automatically optimizes the query to access just the right set of chunks. A database can have multiple hypertables, each with its own schema and partitioning. There's a whitepaper describing the ideas behind TimescaleDB and the way it was designed and works.
More InformationRelated ArticlesPostgreSQL Adds Parallel Query Support PostgreSQL Plus Cloud Database
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin.

Comments
or email your comment to: comments@i-programmer.info |
|||
| Last Updated ( Friday, 31 March 2017 ) |