| BlinkDB Alpha of Approximate Query Engine Released |
| Written by Kay Ewbank |
| Wednesday, 21 August 2013 |
|
The developer alpha of a massively parallel, approximate query engine for running interactive SQL queries on large volumes of data has been released.
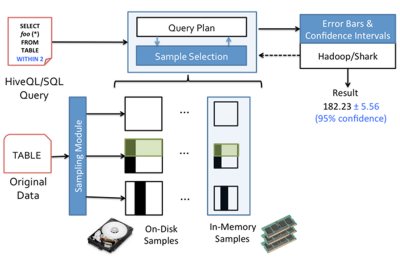
BlinkDB is being developed at the University of California, Berkeley. It is designed to overcome the problem inherent with big data – if the volume of data is massive, running a query against the entire data set will take a very long time. BlinkDB uses sampling, picking a subset of the data so that a user can run an interactive query that gives potentially less accurate results, but where the results appear in an acceptable response time. The results are then shown with meaningful error bars. BlinkDB has two key ideas; firstly, a framework that builds and maintains a set of multi-dimensional samples from original data over time. This framework is adaptive and optimizing to ensure the data set is the best available. The second key idea is a dynamic sample selection strategy that selects an appropriately sized sample based on the users requirements in terms of accuracy and/or response time.
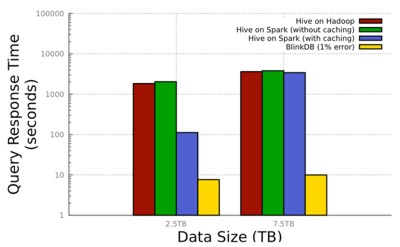
BlinkDB was demonstrated running 200 times faster than Hive at VLDB 2012 on a 100 node Amazon EC2 cluster answering a range of queries on 17TBs of data in less than two seconds within an error of two to 10 per cent. The workload chosen was a set of media access traces from Conviva Inc. The test query simply computed the average of user session times with a filtering predicate on a date column and a GROUP BY on a city column. The team then compared the response time of the full (accurate) execution of this query in Hive on Hadoop and Hive on Spark (Shark) – both with and without caching, against its (approximate) execution on BlinkDB with a 1% error bound for each city at 95% confidence. The results varied from ten times to 200 times faster than its counterparts, depending on the caching, because it is able to read far less data to compute a fairly accurate answer.
The current version of BlinkDB supports a slightly constrained set of SQL-style declarative queries and provides approximate results for standard SQL aggregate queries involving COUNT, AVG, SUM and PERCENTILE. If you run a query that contains these operations, you can specify either an error bound or a time constraint to define how you want the query to run. Based on this qualifier, the system selects an appropriate sample to operate on. The developer alpha of BlinkDB can be downloaded from GitHub You can find out more about BlinkDB, Spark, Shark, Mesos, and other components of the Berkeley Data Analytics Stack at the third AMP Camp Big Data Bootcamp at the end of August. The event runs from August 29-30, 2013 at UC Berkeley, and will also be live streamed and video archived for free. The camp will also include discussions of the newest open-source BDAS projects including MLbase (a user-friendly system for distributed machine learning), GraphX (A Resilient Distributed Graph System on Spark), and Tachyon (a fault tolerant distributed file system enabling reliable file sharing at memory-speed across cluster frameworks). People who attend in person take part in hands-on exercises spanning both days of the event where each attendee is provided with a real compute cluster running on Amazon EC2 with the BDAS software already installed. Attendees then follow step-by-step instructions analyzing real wikipedia data.
More InformationDeveloper Alpha BlinkDB on GitHub Related ArticlesIntroducing Gremlin The Graph Database SQL Server In The Era Of Big Data
To be informed about new articles on I Programmer, install the I Programmer Toolbar, subscribe to the RSS feed, follow us on, Twitter, Facebook, Google+ or Linkedin, or sign up for our weekly newsletter.
Comments
or email your comment to: comments@i-programmer.info

|
| Last Updated ( Wednesday, 21 August 2013 ) |