| Exploring Edison - Fast Memory Mapped I/O |
| Written by Harry Fairhead | |||||
| Wednesday, 23 September 2015 | |||||
Page 1 of 4 Fast memory mapped mode allows the Edison to generate pulses as short as 0.25 microseconds wide and to work with input pulses in the 10-microsecond region. In this chapter we discuss the best way of making use of the fast Atom CPU to work with the GPIO.
This is a chapter from our ebook on the Intel Edison. The full contents can be seen below. Notice this is a first draft and a work in progress.
Now On Sale!You can now buy a print edition of Exploring Intel Edison.You can buy it from:
USA and World Amazon.com Chapter List
<ASIN:1871962447>
In the previous chapter we learned how to make use of the GPIO as simple input and output. The biggest problem we encountered was that everything was on the slow side. There are many applications where this simply doesn't matter because slow in this case means around 100 microseconds to 1 millisecond. Many applications work in near human time and the Edison is plenty fast enough. However there are applications were response times in the microsecond range are essential. For example the well know art of "bit-banging" where you write a program to use the I/O lines to implement some communications protocol. While the Edison has support for I2C for example it lacks native support for alternatives such as the 1-wire bus and custom protocols such as that use with the very useful and popular DHT11 and DHT22 temperature and humidity sensors. In such cases speed is essential if it is going to be possible to write a bit-banging interface. There is also a second issue involved in using the Edison for time critical operations. The fastest pulse you can produce or read depends on the speed of the processor and, as we will see, the Edison's Atom processor is fast enough to generate pulses at the 1 microsecond level. (At the time of writing this seems to be faster than the MCU can work although this might improve with new releases of the SDK.) Another problem is caused by the fact that Linux is not a real time operating system. Linux runs many processes and threads at the same time by allocating each one a small time slice in turn. That is all of the processes that you can see in the process queue (use the ps, command to see a list) each get their turn to run. What this means is that your program could be suspended at any time and it could be suspended for milliseconds. What this means is that if your program is performing a big-banging operation the entire exchange could be brought to a halt by another process that is given the CPU for its time slice. This would cause the protocol to be broken and the only option would be to start over and hope that the transaction could be complete. It is generally stated, often with absolute certainty that you cannot do real time, and big banging in particular under a standard Linux OS, which is what Yocto Linux is. This is true but you can do near real time on any Linux distribution based on the 2.6 kernel or later - i.e. most including the current Yocto. This is easier than you might imagine but there are some subtle problems that you need to know about. In this chapter we tackle the problem of speed both output and input. In the next chapter we tackle smoothing out the glitches by using the Linux scheduler. The mraa Memory Mapped DriverBefore looking at speeding things up let's have a look at how good the current mraa read/write routines are. First we need to know how fast can you toggle the I/O lines?
the line is switched as fast as the software can manage it. In this case the pulse width is about 15 microseconds.
This is reasonable, but notice that this is running under a general purpose Linux and every now and again the program will be suspended while the operating system does something else. In other words, you can generate a 15 microsecond pulse but you can't promise exactly when this will occur. Using a different scale on the logic analyzer, it is fairly easy to find one or more irregularities;
So on this occasion the generated pulse was roughly four times the length of the usual pulse - this is typical for a lightly loaded system, but at can be much worse. Now how do we go about creating a pulse of a given length? There are two general methods. You can use a function that sleeps the thread for a specified time, or you can use a busy wait, i.e. a loop that keeps the thread and just wastes some time looping. usleepThe simplest way of sleeping a thread for a number of microseconds is to use usleep - even if it is deprecated in Posix. To try this, include a call to usleep(10) to delay the pulse:
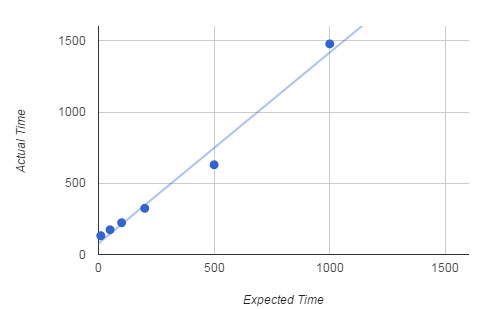
You will discover that adding usleep(10) doesn't increase the pulse length by 10 microseconds but by just over 100 microseconds. You will also discover that the glitches have gone and most of the pulses are about 130 microseconds long. What seems to be happening is that calling usleep yields the thread to the operating system and this incurs an additional 50 microsecond penalty due to calling the scheduler. There are also losses that are dependent on the time you set to wait - usleep only promises that your thread will not restart for at least the specified time. If you look at how the delay time relates to the average pulse length things seem complicated:
You can see that there is a about a 78 microsecond fixed overhead but you also get a delay of roughly 1.34 microseconds for each microsecond you specify. If you want a pulse of length t microseconds then use a delay given by:
Notice that this only accurate to tens of microseconds over the range 100 to 1000 microseconds. Busy waitThe problem with usleep is that it hands the thread over to the operating system which then runs another thread and returns control to your thread only when it is ready to. This works and it smooths out the glitches we saw in the loop without usleep - because usleep yields to the operating system there is no need for it to preempt your thread at other times. An alternative to usleep or any function that yields control to the operating system is to busy wait. In this case your thread stays running on the CPU but the operating system will preempt it and run some other thread. Surprisingly a simple null for loop works very well as a busy wait;
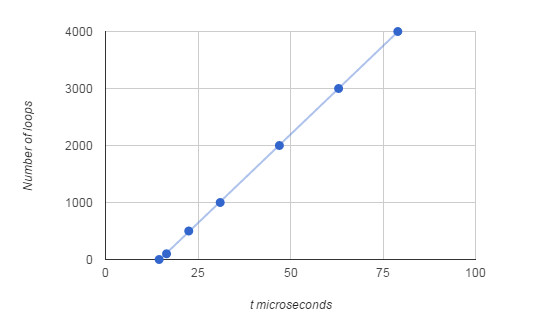
If you try this out you will discover that you can calibrate the number of loops per microsecond delay produced.
If you want to produce a pulse of duration t microseconds then use
loops. For example to create a 100 microsecond pulse you need 62.113*100-912.45 =5299 loops.
This produces pulses that are close to 100 microseconds, roughly in the range 89 to 108 microseconds - but the glitches are back:
We now have pauses in the pulse train that are often 1100 microseconds and very occasionally more. This should not be surprising. We are now keeping the thread for the full amount of time the operating system allows until it preempts our program and runs or contemplates running another thread. At the moment it looks like busy waiting is a good plan but it has problems. The most obvious is that you have to rely on the time to perform one loop not changing. This is something that worries most programmers but if you are targeting a particular cpu there isn't much that happens to change the speed of a for loop. If you are worried about what happens if the Edison is upgraded to a faster clock then you could put a calibration stage in at the start of your program and time how long 5000 loops take and then compute the necessary busy wait parameters for the time periods your program uses. The idea of calibration seems like a good one but it isn't going to be foolproof unless we can find a way to stop the glitches caused by the operating system's scheduler putting arbitrary delays into our program anytime it needs to run another thread - more on this in the next chapter. <ASIN:B00ND1KH42@COM> <ASIN:B00ND1KNXM> <ASIN:B00ND1KH10> |
|||||
| Last Updated ( Tuesday, 10 May 2016 ) |