| Programmer's Guide To Theory - Splitting the Bit |
| Written by Mike James | |||||||
| Monday, 22 July 2024 | |||||||
Page 3 of 3
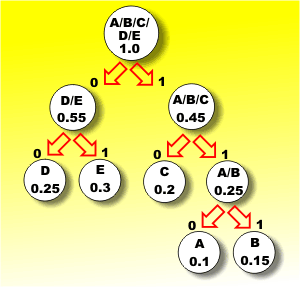
The two symbols that are least likely now are D and E with a combined probability of 0.55. This also completes the coding because there are now only two groups of symbols and we might as well combine these to produce the finished tree.
The final step
This coding tree gives the most efficient representation of the five letters possible. To find the code for a symbol you simply move down the tree reading off the zeros and ones as you go until you arrive at the symbol. To decode a set of bits that has just arrived you start at the top of the tree and take each branch in turn according to whether the bit is a 0 or a 1 until you run out of bits and arrive at the symbol. Notice that the length of the code used for each symbol varies depending on how deep in the tree the symbol is. The theoretical average information in a symbol in this example is 2.3 bits - this is what you get if you work out the average information formula given earlier. If you try to code B you will find that it corresponds to 111, i.e. three bits, and it corresponds to moving down the far right hand branch of the tree. If you code D you will find it corresponds to 00, i.e. the far left hand branch on the tree. In fact each remaining letter is either coded as a two- or three-bit code and guess what? If the symbols occur with their specified probabilities, the average length of code used is 2.3 bits. So we have indeed split the bit! The code we are using averaged 2.3 bits to send a symbol. Notice that there are some problems with variable length codes in that it is more difficult to store them because you need to indicate how many bits are in each group of bits. The most common way of overcoming this is to use code words that have a unique sequence of initial bits. This wastes some code words, but it still generally produces a good degree of data compression. This coding tree gives the most efficient representation of the five letters possible. To find the code for a symbol you simply move down the tree reading off the zeros and ones as you go until you arrive at the symbol. To decode a set of bits that has just arrived you start at the top of the tree and take each branch in turn according to whether the bit is a 0 or a 1 until you run out of bits and arrive at the symbol. Notice that the length of the code used for each symbol varies depending on how deep in the tree the symbol is. The theoretical average information in a symbol in this example is 2.3 bits - this is what you get if you work out the average information formula given earlier. If you try to code B you will find that it corresponds to 111, i.e. three bits, and it corresponds to moving down the far right hand branch of the tree. If you code D you will find it corresponds to 00, i.e. the far left hand branch on the tree. In fact each remaining letter is either coded as a two- or three-bit code and guess what? If the symbols occur with their specified probabilities, the average length of code used is 2.3 bits. So we have indeed split the bit! The code we are using averaged 2.3 bits to send a symbol. Notice that there are some problems with variable length codes in that it is more difficult to store them because you need to indicate how many bits are in each group of bits. The most common way of overcoming this is to use code words that have a unique sequence of initial bits. This wastes some code words, but it still generally produces a good degree of data compression.
Summary
Related ArticlesHow Error Correcting Codes Work Introduction to Cryptography with Open-Source Software A Programmers Guide To Theory
Now available as a paperback and ebook from Amazon.
Contents
Bonus Chapter: What Would P=NP Look Like? ***NEW!
<ASIN:1871962439> <ASIN:1871962587> To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info |
|||||||
| Last Updated ( Monday, 22 July 2024 ) |