| Neural Networks Have A Universal Flaw |
| Written by Mike James | |||
| Friday, 04 November 2016 | |||
|
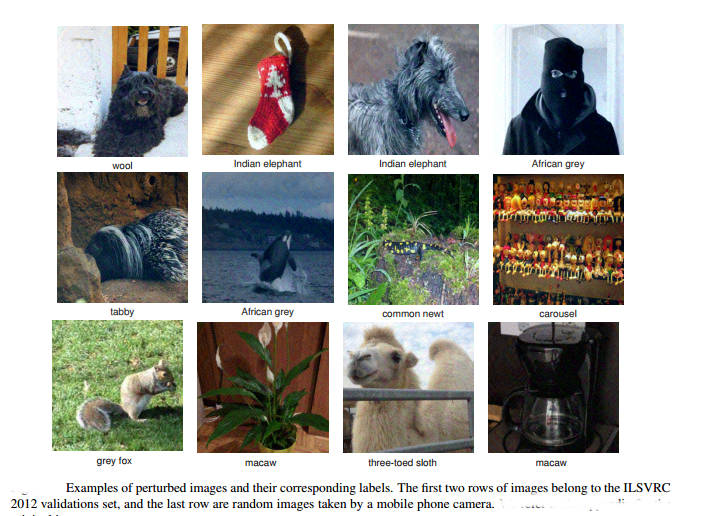
It was recently discovered that neural networks have a flaw that leads them into errors that look stupid to a human. It seems there is a way of modifying any image so that it looks the same to us, but all neural networks will tend to misclassify it. This is the most amazing result AI has produced. UPDATE See below for an informal explanation of what might be the cause and a possible fix. Neural networks learn in a way that generalizes to examples that they haven't seen. If you train a network to recognize a cat using one set of pictures then the network will usually recognize a picture of a cat it has never seen before. The network isn't simply memorizing the training set, it is learning features that enable it to recognize things it has never seen before. As just about everyone even slightly interested in the topic will know, neural networks have been producing some spectacular results - in vision, language understanding, language translation, playing games, and more. There is just one slight worry. About two years ago it was discovered that it was possible to take any input image and find a small modification to its pixel values that caused the network to misclassify the image. The shock factor was that the modification was too small for a human to even notice and so we are faced with two seemingly identical photos, one classified correctly and the other incorrectly in a ridiculous way.
This is disturbing, but you can make the defect seem less by thinking that it is something to do with not training the network enough. Indeed adversarial images, as the slightly modified images are called, are used in training networks to make them better and less sensitive to small changes. Now we have a result that makes it harder to think that the flaw is an artifact. Something strange is going on. The new result is startling. Researchers from École Polytechnique Fédérale de Lausanne (EFPL) have discovered that there are universal perturbations. That is, you can take a neural network trained on a set of images and find an image, with small pixel values, that you can add to any other image that causes it to be misclassified with high probability. This universal adversarial perturbation is independent of the image you want the network to misclassify. What is even more worrying is that it is largely independent of the neural network being used.
There isn't just one universal adversarial perturbation, the algorithm finds one particular vector that will do the job. If you set it off again it can find others. You don't even have to show the algorithm the entire training set to find such perturbations, as few as one photo from each class seems to be enough - although the more you use the better the chance of finding a good universal perturbation. You can read the paper if you want the fine details ,but the conclusion is that there exist universal adversarial perturbations for the general class of natural images that will change the classification seemingly irrespective of the details of the neural network. This is almost like discovering a new law of nature. As the result is largely independent of way the classification is learned, it has to be a property of the images. What it seems to be telling us is that the statistics of natural images is such that the decision boundaries - the surfaces in the high-dimensional data space - are such that there are a small number of directions in which a very small step takes you across the boundary. To put it another way, the distribution of images and classification boundaries is such that there are directions in which a small translation has a high probability of crossing the boundary. Stating it in yet other words, there exist directions in which every point in the space is very close to its correct class boundary, making it easy to shift them beyond it, What do these perturbations look like:
You can see that these samples are different but they have a characteristic look. Just to emphasise how strange this result is - you can take any one of the above images and add it to an image that the network correctly classifies with a high probability of changing its classification without altering the way it looks to a human.
This is probably the most important finding about the nature of neural networks and we need to find out what it means for artificial vision and the statistics of natural images, in particular. UpdateA Possible Explanation And FixMike James adds: Having reported this fascinating finding and problem I wanted to make a comment. But rather than submitting it to the usual comment area, I've included it here: Consider the classification task: divide the high dimensional space of nxm images into c categories. This divides the entire space into c regions defining category boundaries. The fact that the entire space is divided is important because the class of natural images, i.e. those that actually occur in the world, occupies only a small region of the entire space. In other words, most images are not recognizable as natural images - they are noise or artificial patterns rather than dogs, cats or cars. So there is also a division of the space into natural and non-natural images which is independent of any classification method that is used to sub-divide the subspace of natural images. This division is a fundamental property of the world. This implies that there are directions that take you from the natural to the non-natural subspaces, which are independent of classification method used in the natural subspace. These vectors are obviously members of the non-natural subspace and there will be examples with a small magnitude. These are the universal adversarial perturbation vectors. Adding one of these vectors to a natural image moves it into the unnatural subspace, where is has a high probability of being misclassified - remember that the entire space is divided by the classifier not just the valid natural subspace. The classification in the non-natural region of the space is likely to be random because it has no natural structure - i.e. it doesn't look like a dog or a cat as it is a semi-regular noise-like artificial pattern. The solution to the problem is to not extend the classifiers into the non-natural region. This can be done by including a non-natural training set and category. So when shown a natural image modified by a universal adversarial perturbation the neural net should output a "non-natural or tampered with" category. This would be accurate, in the sense that the image has been tampered with even though a human cannot perceive this fact, and would remove the problem by detecting natural images with non-natural patterning. This raises a further question for research: why don't humans perceive the doctored image as "non-natural or tampered with"? If you want to contribute to this discussion, please use the comment form, or if too long email mike.james@i-programmer.info.
More InformationUniversal adversarial perturbations Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, Pascal Frossard Related ArticlesThe Flaw In Every Neural Network Just Got A Little Worse The Deep Flaw In All Neural Networks The Flaw Lurking In Every Deep Neural Net Neural Networks Describe What They See Neural Turing Machines Learn Their Algorithms Google's Deep Learning AI Knows Where You Live And Can Crack CAPTCHA Google Uses AI to Find Where You Live Deep Learning Researchers To Work For Google Google Explains How AI Photo Search Works Google Has Another Machine Vision Breakthrough?
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on, Twitter, Facebook, Google+ or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Friday, 04 November 2016 ) |