| GANs Create Talking Avatars From One Photo |
| Written by Mike James | |||
| Saturday, 25 May 2019 | |||
|
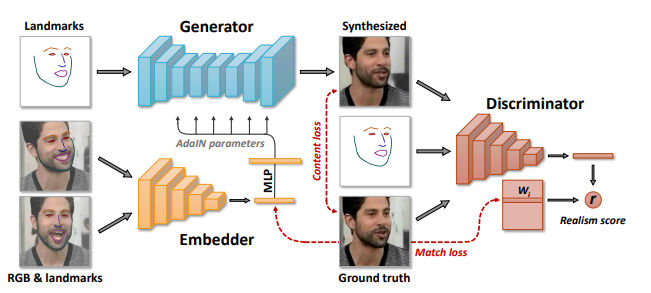
Just when you thought it couldn't get any creepier, researchers at Samsung have managed to use a neural network to create realistic talking heads from a single photo of the subject. You really cannot rely on what you see any more. Deepfakes just got more sophisticated with the help of adversarial networks. The system takes some still photos of a person and can generate a talking head that looks like the person, but is controlled by the facial landmarks of the same or a different person. Essentially, you give them a photo of yourself and they can create realistic video of you saying whatever they want you to say. The principle is that the system is first trained using frames from a video of a particular person, complete with facial landmarks. After some training, the generator attempts to construct a synthetic image from a facial landmark image for a frame not used in the training. The result is compared to the real frame and the discriminator network feeds back a realism score, which is used to improve the generator.
Once the "meta learning" phase is complete, i.e. it has converged on the training video frames, a set of photos of a person, not in the training set, can be input and the system attempts to create a synthetic image based on the photo and its landmark data. Again, training is performed on the basis of how well the system matches ground truth. The number of training photos at this stage can be very small and it seems to work with just one training photo - i.e. one-shot learning. After this, you can input landmark data obtained from another face and create images that don't correspond to any that you have shown the network - i.e. you can puppeteer the face. Although the method works for one-shot learning, it does better with more photos, although in practice the number is quite small. Take a look at the results: So should we be worried? The experimenters seem to be as they write: "We realize that our technology can have a negative use for the so-called “deepfake” videos. However, it is important to realize, that Hollywood has been making fake videos (aka “special effects”) for a century, and deep networks with similar capabilities have been available for the past several years (see links in the paper). Our work (and quite a few parallel works) will lead to the democratization of the certain special effects technologies. And the democratization of the technologies has always had negative effects." They go on to say that they believe that the overall effect of the technology will be positive and they cite the development of deepfake detection technology as something that might protect us from the worst. OK so animating people from paintings and the like is fun, but what are the real uses? "We believe that telepresence technologies in AR, VR and other media are to transform the world in the not-so-distant future. Shifting a part of human life-like communication to the virtual and augmented worlds will have several positive effects." The basic idea seems to be that rather than sending video down the line, we can send a landmark map and create a photorealistic avatar at the receiving end. I'm not sure that in its basic form this is a compelling application, but it might be. What will excite most people is the idea that they could appear in telepresense, AR or VR as someone else with more "presence" than they naturally possess. A way to overcome a poor stage presence, say. What if all your lectures were delivered by Albert Einstein?
More InformationFew-Shot Adversarial Learning of Realistic Neural Talking Head Models Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, Victor Lempitsky Related ArticlesAI News Anchor - A First For China Deep Angel-The AI of Future Media Manipulation More Efficient Style Transfer Algorithm 3D Face Reconstruction Applied to Art Find Your 2000-Year-Old Double With Face Recognition A Neural Net Creates Movies In The Style Of Any Artist Style Transfer Applied To Cooking - The Case Of The French Sukiyaki
To be informed about new articles on I Programmer, sign up for our weekly newsletter, subscribe to the RSS feed and follow us on Twitter, Facebook or Linkedin. 
Comments
or email your comment to: comments@i-programmer.info
|
|||
| Last Updated ( Sunday, 26 May 2019 ) |