• Cooperation among competitors in the open-source arena: The Case of OpenStack
Sometimes the news is reported well enough elsewhere and we have little to add other than to bring it to your attention.
No Comment is a format where we present original source information, lightly edited, so that you can decide if you want to follow it up.
Who wrote what? It is an important question if only to make sure we can apportion blame accordingly! We have two new pieces of research concerned with who wrote what and another looking at how companies cooperate in an open source project.
The first gives some insight into who does what in the Linux kernel project and this is taken as a typical open source project. The second demonstrates that you can identify a programmer from a snippet of code which has some worrying implications. The third gives a great deal of insight into the OpenStack project.
Code authorship is a key information in large-scale open source systems. Among others, it allows maintainers to assess division of work and identify key collaborators.
Interestingly, open-source communities lack guidelines on how to manage authorship. This could be mitigated by setting to build an empirical body of knowledge on how authorship-related measures evolve in successful open-source communities.
Towards that direction, we perform a case study on the Linux kernel. Our results show that:
(a) only a small portion of developers (26 %) makes significant contributions to the code base;
(b) the distribution of the number of files per author is highly skewed --- a small group of top authors (3 %) is responsible for hundreds of files, while most authors (75 %) are responsible for at most 11 files;
(c) most authors (62 %) have a specialist profile;
(d) authors with a high number of co-authorship connections tend to collaborate with others with less connections.
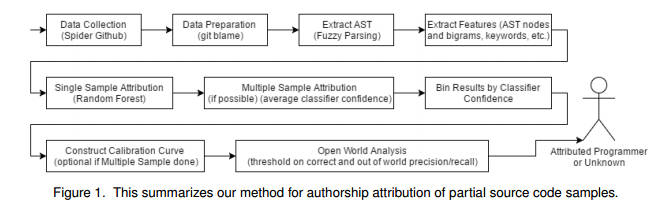
Program authorship attribution has implications for the privacy of programmers who wish to contribute code anonymously. While previous work has shown that complete files that are individually authored can be attributed, we show here for the first time that accounts belonging to open source contributors containing short, incomplete, and typically uncompilable fragments can also be effectively attributed.
We propose a technique for authorship attribution of contributor accounts containing small source code samples, such as those that can be obtained from version control systems or other direct comparison of sequential versions. We show that while application of previous methods to individual small source code samples yields an accuracy of about 73% for 106 programmers as a baseline, by ensembling and averaging the classification probabilities of a sufficiently large set of samples belonging to the same author we achieve 99% accuracy for assigning the set of samples to the correct author.
Through these results, we demonstrate that attribution is an important threat to privacy for programmers even in real-world collaborative environments such as GitHub. Additionally, we propose the use of calibration curves to identify samples by unknown and previously unencountered authors in the open world setting. We show that we can also use these calibration curves in the case that we do not have linking information and thus are forced to classify individual samples directly. This is because the calibration curves allow us to identify which samples are more likely to have been correctly attributed. Using such a curve can help an analyst choose a cut-off point which will prevent most misclassifications, at the cost of causing the rejection of some of the more dubious correct attributions.
Interorganizational interactions are often complex and paradoxical. In this research, we transcend two management paradoxes: competition versus cooperation and open-source versus proprietary technology development.
We follow the OpenStack open-source ecosystem where competing firms cooperate in the joint-development of a cloud infrastructure for big data. We provide a narrative, complemented with social network visualizations, which depicts the evolution of cooperation and competition.
Our findings suggest that development transparency and weak intellectual property rights (i.e., characteristics of open-source ecosystems) allow a focal firm to transfer information and resources more easily between multiple alliances.
GitLab 18 has been released with extensions to the Duo AI-based assistant. The news was followed by reports that Duo had a security vulnerability that provided a route for attackers. The problem has n [ ... ]